Mostrando entradas con la etiqueta Cursos. Mostrar todas las entradas
Mostrando entradas con la etiqueta Cursos. Mostrar todas las entradas
jueves, 8 de mayo de 2008
 Si queremos eliminar un vídeo que haya sido publicado por nosotros previamente en Youtube lo primero que debemos hacer es entrar con nuestro usuario. Luego es necesario abrir la lista Mis vídeos, que contiene los vídeos que hemos publicado. Esta opción se encuentra en el menú Cuenta, y se muestra marcada con un borde rojo, en la imagen siguiente:
Si queremos eliminar un vídeo que haya sido publicado por nosotros previamente en Youtube lo primero que debemos hacer es entrar con nuestro usuario. Luego es necesario abrir la lista Mis vídeos, que contiene los vídeos que hemos publicado. Esta opción se encuentra en el menú Cuenta, y se muestra marcada con un borde rojo, en la imagen siguiente:
 Una vez que hayamos entrado al menú Mis vídeos tendremos la lista de todos los vídeos que hemos publicados en Youtube, para eliminar uno o varios bastará con hacer clic en el botón Retirar vídeo que aparece debajo de cada uno. En la imagen siguiente este botón se muestra marcado con un borde rojo:
Una vez que hayamos entrado al menú Mis vídeos tendremos la lista de todos los vídeos que hemos publicados en Youtube, para eliminar uno o varios bastará con hacer clic en el botón Retirar vídeo que aparece debajo de cada uno. En la imagen siguiente este botón se muestra marcado con un borde rojo:
 Después de hacer clic en este botón el navegador nos pedirá una confirmación para eliminarlo definitivamente que debemos aceptar para continuar. Luego de aceptar esta confirmación el vídeo habrá desaparecido de los servidores de Youtube para siempre.
Continuar leyendo
Después de hacer clic en este botón el navegador nos pedirá una confirmación para eliminarlo definitivamente que debemos aceptar para continuar. Luego de aceptar esta confirmación el vídeo habrá desaparecido de los servidores de Youtube para siempre.
Continuar leyendo
martes, 6 de mayo de 2008
Generalmente, y en más de una ocasión necesitamos publicar algún video en la internet; ya sea para compartirlo con los amigos, verlo más tarde, almacenarlo, guardarlo en un lugar seguro o por cualquier otro motivo. A continuación explicaremos en unos pocos pasos cómo subir archivos de video utilizando el popular servicio de publicación online Youtube.
Lo primero que debemos hacer es registrarnos o entrar con nuestro usuario si es que ya tenemos una cuenta en Youtube. El registro es relativamente sencillo y no requiere de ningún conocimiento especial.
Luego debemos hacer clic en el botón amarillo Subir que aparece en la parte superior derecha del sitio, como se muestra en la imagen siguiente:
 Una vez que hayamos pinchado en el botón Subir se nos pedirá la información del vídeo en dos pasos:
En el primero debemos especificar de forma obligatoria el título, la descripción, la categoría y las etiquetas que más se asemejen al contenido de nuestro vídeo. Las etiquetas que se muestran están en correspondencia con la categoría que hayamos seleccionado previamente. Aunque no es obligatorio, también podremos definir las opciones de emisión, opciones de mapa y fechas, y las opciones para compartir que detallaremos a continuación:
Opciones de emisión: puede ser público, para que nuestro vídeo sea visto por cualquier persona, o privado y en este último caso sólo será visible para el usuario que sube el vídeo y otros 25 que podremos seleccionar de nuestra lista de contactos en Youtube. Si no especificamos esta opción, Youtube asume por defecto que el vídeo es público y lo podrá ver todo el mundo.
Opciones de mapa y fechas: podremos especificar la fecha de grabación del vídeo. Además nos proporciona un mapa de Google Maps, donde podremos definir la ubicación geográfica donde se grabó.
Opciones para compartir: configurando estas opciones podremos determinar si queremos que los comentarios de este vídeo sean publicados automáticamente, si deben ser aprobados antes de publicarse, si se publicarán automáticamente los comentarios de los amigos y los demás necesitarán aprobación o si no permitiremos comentarios; por defecto se permiten los comentarios sin la necesidad de ningún nivel de aprobación. También es posible permitir o no que los usuarios voten en los comentarios; por defecto se permite. Las respuestas en vídeo pueden publicarse de forma automática, una vez que se hayan aprobado o no permitirse; por defecto está definida la primera posibilidad. Además podremos permitir o no que se le pueda dar una puntuación al vídeo. Es posible determinar si queremos que nuestro vídeo se pueda insertar y reproducir en sitios externos. Y por último, también es posible hacer que el vídeo esté disponible para dispositivos móviles y sistemas de TV.
Luego de establecer estas características del vídeo, podemos proceder a subirlo. Es posible hacerlo directamente de nuestro ordenador haciendo clic en el botón Subir un vídeo o utilizando el método de Captura rápida que nos permite subirlos desde un dispositivo de video conectado a nuestro ordenador, como una cámara web o una video cámara y para esto debemos hacer clic en el botón Utilizar Captura rápida que se muestra al final del formulario.
Subir un vídeo
Si queremos subir el vídeo desde nuestro ordenador, debemos hacer clic en el botón Subir un vídeo, que aparece a la izquierda. Luego se nos pedirá que seleccionemos el video que queremos subir utilizando el botón Examinar podremos llegar hasta él. Después de seleccionarlo hagamos clic en Subir vídeo para que Youtube comience a guardar el vídeo en sus servidores. Cuando el proceso se haya completado nos mostrará un mensaje haciéndonos saber que ha finalizado y nos proporcionará un código HTML que podremos poner en cualquier parte de un sitio web donde queramos que se muestre el vídeo.
Luego podremos agregar otro vídeo o ir a la sección Mis vídeos, donde se guardan los que hemos subido a Youtube.
Utilizar Captura rápida
Si escogemos el método de captura rápida podremos subir los vídeos directamente desde nuestra cámara a Youtube. Para esto, luego de hacer clic en el botón de la derecha, se nos muestra un control de videos flash que nos pregunta si vamos a permitir que Youtube acceda a nuestra cámara y micrófono; debemos permitirlo ya que de otra forma no podremos continuar con la publicación del vídeo. Debemos seleccionar en la parte superior del control el dispositivo de video y audio que utilizaremos para la grabación.
Antes de seleccionar esta opción es importante asegurarnos que nuestra cámara está conectada al ordenador y funciona bien.
Una vez que el vídeo está publicado en Youtube por cualquiera de las dos vías, se podrá enviar el enlace a nuestros amigos para que lo disfruten, podremos organizarlo en cualquiera de nuestras listas de reproducción, publicarlo en un sitio web utilizando el código HTML que nos provee Youtube, editar las opciones y la configuración en general del vídeo.
Continuar leyendo
Una vez que hayamos pinchado en el botón Subir se nos pedirá la información del vídeo en dos pasos:
En el primero debemos especificar de forma obligatoria el título, la descripción, la categoría y las etiquetas que más se asemejen al contenido de nuestro vídeo. Las etiquetas que se muestran están en correspondencia con la categoría que hayamos seleccionado previamente. Aunque no es obligatorio, también podremos definir las opciones de emisión, opciones de mapa y fechas, y las opciones para compartir que detallaremos a continuación:
Opciones de emisión: puede ser público, para que nuestro vídeo sea visto por cualquier persona, o privado y en este último caso sólo será visible para el usuario que sube el vídeo y otros 25 que podremos seleccionar de nuestra lista de contactos en Youtube. Si no especificamos esta opción, Youtube asume por defecto que el vídeo es público y lo podrá ver todo el mundo.
Opciones de mapa y fechas: podremos especificar la fecha de grabación del vídeo. Además nos proporciona un mapa de Google Maps, donde podremos definir la ubicación geográfica donde se grabó.
Opciones para compartir: configurando estas opciones podremos determinar si queremos que los comentarios de este vídeo sean publicados automáticamente, si deben ser aprobados antes de publicarse, si se publicarán automáticamente los comentarios de los amigos y los demás necesitarán aprobación o si no permitiremos comentarios; por defecto se permiten los comentarios sin la necesidad de ningún nivel de aprobación. También es posible permitir o no que los usuarios voten en los comentarios; por defecto se permite. Las respuestas en vídeo pueden publicarse de forma automática, una vez que se hayan aprobado o no permitirse; por defecto está definida la primera posibilidad. Además podremos permitir o no que se le pueda dar una puntuación al vídeo. Es posible determinar si queremos que nuestro vídeo se pueda insertar y reproducir en sitios externos. Y por último, también es posible hacer que el vídeo esté disponible para dispositivos móviles y sistemas de TV.
Luego de establecer estas características del vídeo, podemos proceder a subirlo. Es posible hacerlo directamente de nuestro ordenador haciendo clic en el botón Subir un vídeo o utilizando el método de Captura rápida que nos permite subirlos desde un dispositivo de video conectado a nuestro ordenador, como una cámara web o una video cámara y para esto debemos hacer clic en el botón Utilizar Captura rápida que se muestra al final del formulario.
Subir un vídeo
Si queremos subir el vídeo desde nuestro ordenador, debemos hacer clic en el botón Subir un vídeo, que aparece a la izquierda. Luego se nos pedirá que seleccionemos el video que queremos subir utilizando el botón Examinar podremos llegar hasta él. Después de seleccionarlo hagamos clic en Subir vídeo para que Youtube comience a guardar el vídeo en sus servidores. Cuando el proceso se haya completado nos mostrará un mensaje haciéndonos saber que ha finalizado y nos proporcionará un código HTML que podremos poner en cualquier parte de un sitio web donde queramos que se muestre el vídeo.
Luego podremos agregar otro vídeo o ir a la sección Mis vídeos, donde se guardan los que hemos subido a Youtube.
Utilizar Captura rápida
Si escogemos el método de captura rápida podremos subir los vídeos directamente desde nuestra cámara a Youtube. Para esto, luego de hacer clic en el botón de la derecha, se nos muestra un control de videos flash que nos pregunta si vamos a permitir que Youtube acceda a nuestra cámara y micrófono; debemos permitirlo ya que de otra forma no podremos continuar con la publicación del vídeo. Debemos seleccionar en la parte superior del control el dispositivo de video y audio que utilizaremos para la grabación.
Antes de seleccionar esta opción es importante asegurarnos que nuestra cámara está conectada al ordenador y funciona bien.
Una vez que el vídeo está publicado en Youtube por cualquiera de las dos vías, se podrá enviar el enlace a nuestros amigos para que lo disfruten, podremos organizarlo en cualquiera de nuestras listas de reproducción, publicarlo en un sitio web utilizando el código HTML que nos provee Youtube, editar las opciones y la configuración en general del vídeo.
Continuar leyendo
sábado, 26 de abril de 2008
Los vídeos que subimos a Youtube pueden tener un tamaño de hasta 100MB si los subimos uno a uno desde el sitio web; también podemos utilizar YouTube Uploader para la subida de varios vídeos de un solo golpe y en este caso los vídeos pueden tener un tamaño máximo de 1GB.
Para reducir el tamaño de un vídeo que no cumpla con los requerimientos anteriores podemos disminuirlo comprimiéndolo con un programa de edición de vídeo como Windows Movie Maker, que viene preinstalado en los ordenadores con Windows XP, que además nos permite editar la banda sonora de la película, insertar o eliminar fotogramas y comprimir los archivos. Es importante tener en cuenta que mientras más se comprima un vídeo, menor calidad de audio y video tendrá éste.
El principal problema a la hora de subir nuestros vídeos a Youtube, por cualquiera de los métodos que utilicemos está en que sólo pueden tener un máximo de 10 minutos de duración cada vídeo y eso no existe forma de obviarlo.
Si quiere conocer cómo descargar vídeos de Youtube para su ordenador o simplemente quemarlos en CD/DVD, haga clic en el siguiente título:
domingo, 20 de abril de 2008
En el artículo anterior conocimos cómo comprobar el estado de nuestra conexión, así como los elementos más importantes de la ventana de estado. Haciendo clic en el botón propiedades que aparece en dicha ventana podremos acceder a características más avanzadas de nuestra conexión, como se muestra en la imagen que aparece a continuación:
 Aquí detallaremos los elementos más importantes de esta ventana. A todos se accede haciendo doble clic encima.
Aquí detallaremos los elementos más importantes de esta ventana. A todos se accede haciendo doble clic encima.
- Clientes para redes de Microsoft: éste elemento siempre deberá estar marcado ya que le indica a nuestra PC que nos conectaremos a una red de equipos con Windows.
- Compartir impresoras y archivos para redes Microsoft: si este elemento se encuentra marcado podremos compartir archivos e impresoras con otras computadoras de la red. Si se desactiva esta opción desde otras máquinas de la red no podrán imprimir con nuestras impresoras ni ver nuestras carpetas compartidas.
- Programador de paquetes QoS: éste es un servicio que nos permite tener mantener en equilibrio la carga de la red, pero no es imprescindible.
- Protocolo Internet (TCP/IP): éste elemento nos permite configurar parámetros de nuestra conexión como la dirección IP, la máscara de red, puerta de enlace, servidores de nombres (DNS) y servidores WINS.
 También tenemos la solapa “Opciones avanzadas” en esa ventana y en ella podemos configurar el Firewall de nuestra conexión de red para proteger nuestro ordenador de ataques externos, virus y accesos no autorizados.
También tenemos la solapa “Opciones avanzadas” en esa ventana y en ella podemos configurar el Firewall de nuestra conexión de red para proteger nuestro ordenador de ataques externos, virus y accesos no autorizados.
 Además podremos compartir esta conexión con otro ordenador de la red, a través de otra conexión de red, para esto es necesario tener al menos dos conexiones activas.
Continuar leyendo
Además podremos compartir esta conexión con otro ordenador de la red, a través de otra conexión de red, para esto es necesario tener al menos dos conexiones activas.
Continuar leyendo
sábado, 19 de abril de 2008
En el artículo anterior nos conectamos al punto de acceso que seleccionamos. Una vez conectados debemos comprobar que nuestra conexión funciona correctamente y precisamente a esto dedicaremos éste artículo.
Para comprobar el estado de nuestra conexión debemos hacer clic derecho en el icono de la barra de tareas de la conexión inalámbrica (el mismo del capítulo 2) y del menú que nos muestra hagamos clic sobre la opción “Estado”, como se muestra en la imagen siguiente.
 A continuación se nos mostrará la ventana con los detalles del estado de la conexión. Como podremos ver en la imagen que sigue:
A continuación se nos mostrará la ventana con los detalles del estado de la conexión. Como podremos ver en la imagen que sigue:

- Estado: Muestra si nuestro punto de acceso está conectado, desconectado o si tiene algún problema.
- Red: Especifica el nombre de la red a la que nos hemos conectado. Muy útil cuando establecemos conexiones con varias redes al mismo tiempo o tenemos varias tarjetas de red en el equipo.
- Duración: Es el tiempo que llevamos conectados a ésta red.
- Velocidad: Nos indica la velocidad de la conexión. Existen redes inalámbricas a 11Mbps, 54Mbps y las más recientes soportan hasta 108 Mega bits por segundo.
- Además nos muestra la intensidad de la señal. Esto se refiere a la calidad con que llega la onda de radio de la conexión hasta nuestra posición. Si la intensidad está muy baja podremos aumentarla acercándonos físicamente al punto de acceso que nos hemos conectado.
viernes, 18 de abril de 2008
En el artículo anterior exploramos en busca de redes inalámbricas disponibles y encontramos una con disponibilidad para conectarnos. Pues en este capítulo describiremos los pasos para conectarnos correctamente a la red detectada.
En la ventana donde nos muestra el listado de conexiones encontradas hacemos clic sobre la conexión que nos interesa y pinchamos sobre el botón “Conectar” que aparece en la parte inferior derecha de la ventana. Una vez hecho esto, y si la conexión está configurada con la seguridad adecuada nos pedirá que ingresemos la contraseña para conectarnos, como aparece en la imagen siguiente:
 Luego de escribir la clave de red debemos hacer clic en el botón “Conectar” e inmediatamente se comenzará a establecer la conexión entre nuestro equipo y el punto de acceso que seleccionamos.
Luego de escribir la clave de red debemos hacer clic en el botón “Conectar” e inmediatamente se comenzará a establecer la conexión entre nuestro equipo y el punto de acceso que seleccionamos.
 Cuando el proceso termine podremos ver que el estado de la red, en el listado ha cambiado y ahora lo vemos “Conectado”.
Cuando el proceso termine podremos ver que el estado de la red, en el listado ha cambiado y ahora lo vemos “Conectado”.
 Luego de configurar correctamente nuestra red inalámbrica es necesario chequear que todo está funcionando en orden, para esto veremos en el próximo artículo cómo comprobar el estado de nuestra conexión.
Continuar leyendo
Luego de configurar correctamente nuestra red inalámbrica es necesario chequear que todo está funcionando en orden, para esto veremos en el próximo artículo cómo comprobar el estado de nuestra conexión.
Continuar leyendo
jueves, 17 de abril de 2008
En este artículo comenzaremos la configuración de nuestra red inalámbrica. Primeramente debemos asegurarnos que nuestro punto de acceso esté encendido y que dispongamos de una tarjeta de red inalámbrica en nuestro ordenador. Luego buscaremos en nuestro escritorio el icono que resaltamos con un borde rojo en la imagen que se muestra a continuación:
 Hagamos clic derecho sobre el icono y veremos el menú de la imagen siguiente. Seleccionemos la opción resaltada Ver redes inalámbricas disponibles.
Hagamos clic derecho sobre el icono y veremos el menú de la imagen siguiente. Seleccionemos la opción resaltada Ver redes inalámbricas disponibles.
 Inmediatamente después de esto se nos mostrará la ventana de búsqueda de redes que aparece en la imagen siguiente:
Inmediatamente después de esto se nos mostrará la ventana de búsqueda de redes que aparece en la imagen siguiente:
 Durante unos minutos el sistema explorará el entorno en busca de puntos de acceso disponibles para realizar una conexión. Una vez terminada esta exploración mostrará una lista de las redes encontradas, como se muestra en la imagen siguiente:
Durante unos minutos el sistema explorará el entorno en busca de puntos de acceso disponibles para realizar una conexión. Una vez terminada esta exploración mostrará una lista de las redes encontradas, como se muestra en la imagen siguiente:
 Una vez encontrada al menos una red disponible podremos establecer la conexión. En el próximo artículo explicaremos cómo conectarnos a la red inalámbrica seleccionada.
Continuar leyendo
Una vez encontrada al menos una red disponible podremos establecer la conexión. En el próximo artículo explicaremos cómo conectarnos a la red inalámbrica seleccionada.
Continuar leyendo
miércoles, 16 de abril de 2008
En este manual exponemos la manera más rápida de configurar una red inalámbrica para lograr conectarnos en pocos minutos.
Antes de adentrarnos en la configuración de nuestra red inalámbrica debemos conocer brevemente algunos puntos interesantes sobre estos tipos de conexiones.
¿Qué es una red inalámbrica?
A grandes rasgos una red inalámbrica es la conexión que se establece entre dos o más dispositivos en los que la transmisión de información se realiza sin intervención de cables. Generalmente este tipo de comunicación se realiza a través de ondas de radio.
¿Qué es Wi-Fi?
Wi-Fi, abreviatura de Wireless Fidelity; es una marca comercial de la Wi-Fi Alliance, con este logo se certifica que los productos cumplen los estandares de redes Inalámbricas IEEE 802.11.
Punto de acceso y estación
Las conexiones sin cables funcionan de una manera que siempre es necesario que exista un punto de acceso para que los dispositivos que integrarán la red se conecten a éste. A manera de ejemplo un punto de acceso puede ser un router inalámbrico, un switch inalámbrico o simplemente una tarjeta de red configurada para este fin. Una vez que exista un punto de acceso se podrán conectar entre sí computadoras, impresoras, teléfonos, agendas y todos los dispositivos que tengan implementado el sistema inalámbrico.
En la imagen siguiente mostramos un diagrama de cómo funciona una red inalámbrica. Como podrá ver el del centro es el punto de acceso.
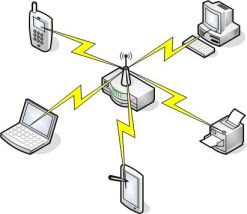 Ya tenemos los conocimientos necesarios para la configuración de nuestra red, en el próximo artículo comenzaremos a realizar la configuración de nuestra red inalámbrica.
Continuar leyendo
Ya tenemos los conocimientos necesarios para la configuración de nuestra red, en el próximo artículo comenzaremos a realizar la configuración de nuestra red inalámbrica.
Continuar leyendo
sábado, 29 de marzo de 2008
 El 24 de Octubre de 1995, el FNC (Federal Networking Council, Consejo Federal de la Red) aceptó unánimemente una resolución definiendo el término Internet. La definición se elaboró de acuerdo con personas de las áreas de Internet y los derechos de propiedad intelectual. La resolución: "el FNC acuerda que lo siguiente refleja nuestra definición del término Internet. Internet hace referencia a un sistema global de información que:
El 24 de Octubre de 1995, el FNC (Federal Networking Council, Consejo Federal de la Red) aceptó unánimemente una resolución definiendo el término Internet. La definición se elaboró de acuerdo con personas de las áreas de Internet y los derechos de propiedad intelectual. La resolución: "el FNC acuerda que lo siguiente refleja nuestra definición del término Internet. Internet hace referencia a un sistema global de información que:
- Está relacionado lógicamente por un único espacio de direcciones global basado en el protocolo de Internet (IP) o en sus extensiones.
- Es capaz de soportar comunicaciones usando el conjunto de protocolos TCP/IP o sus extensiones u otros protocolos compatibles con IP.
- Emplea, provee, o hace accesible, privada o públicamente, servicios de alto nivel en capas de comunicaciones y otras infraestructuras relacionadas aquí descritas".
 Esta evolución nos traerá una nueva aplicación: telefonía Internet y, puede que poco después, televisión por Internet. Está permitiendo formas más sofisticadas de valoración y recuperación de costes, un requisito fundamental en la aplicación comercial. Está cambiando para acomodar una nueva generación de tecnologías de red con distintas características y requisitos: desde ancho de banda doméstico a satélites. Y nuevos modos de acceso y nuevas formas de servicio que darán lugar a nuevas aplicaciones, que, a su vez, harán evolucionar a la propia red.
La cuestión más importante sobre el futuro de Internet no es cómo cambiará la tecnología, sino cómo se gestionará esa evolución. En este capítulo se ha contado cómo un grupo de diseñadores dirigió la arquitectura de Internet y cómo la naturaleza de ese grupo varió a medida que creció el número de partes interesadas. Con el éxito de Internet ha llegado una proliferación de inversores que tienen intereses tanto económicos como intelectuales en la red. Se puede ver en los debates sobre el control del espacio de nombres y en la nueva generación de direcciones IP una pugna por encontrar la nueva estructura social que guiará a Internet en el futuro. Será difícil encontrar la forma de esta estructura dado el gran número de intereses que concurren en la red. Al mismo tiempo, la industria busca la forma de movilizar y aplicar las enormes inversiones necesarias para el crecimiento futuro, por ejemplo para mejorar el acceso del sector residencial. Si Internet sufre un traspiés no será debido a la falta de tecnología, visión o motivación. Será debido a que no podemos hallar la dirección justa por la que marchar unidos hacia el futuro.
Continuar leyendo
Esta evolución nos traerá una nueva aplicación: telefonía Internet y, puede que poco después, televisión por Internet. Está permitiendo formas más sofisticadas de valoración y recuperación de costes, un requisito fundamental en la aplicación comercial. Está cambiando para acomodar una nueva generación de tecnologías de red con distintas características y requisitos: desde ancho de banda doméstico a satélites. Y nuevos modos de acceso y nuevas formas de servicio que darán lugar a nuevas aplicaciones, que, a su vez, harán evolucionar a la propia red.
La cuestión más importante sobre el futuro de Internet no es cómo cambiará la tecnología, sino cómo se gestionará esa evolución. En este capítulo se ha contado cómo un grupo de diseñadores dirigió la arquitectura de Internet y cómo la naturaleza de ese grupo varió a medida que creció el número de partes interesadas. Con el éxito de Internet ha llegado una proliferación de inversores que tienen intereses tanto económicos como intelectuales en la red. Se puede ver en los debates sobre el control del espacio de nombres y en la nueva generación de direcciones IP una pugna por encontrar la nueva estructura social que guiará a Internet en el futuro. Será difícil encontrar la forma de esta estructura dado el gran número de intereses que concurren en la red. Al mismo tiempo, la industria busca la forma de movilizar y aplicar las enormes inversiones necesarias para el crecimiento futuro, por ejemplo para mejorar el acceso del sector residencial. Si Internet sufre un traspiés no será debido a la falta de tecnología, visión o motivación. Será debido a que no podemos hallar la dirección justa por la que marchar unidos hacia el futuro.
Continuar leyendo
viernes, 28 de marzo de 2008
 La comercialización de Internet llevaba acarreada no sólo el desarrollo de servicios de red privados y competitivos sino también el de productos comerciales que implementen la tecnología Internet. A principios de los años 80 docenas de fabricantes incorporaron TCP/IP a sus productos debido a la aproximación de sus clientes a esta tecnología de redes. Desafortunadamente, carecían de información fiable sobre cómo funcionaba esta tecnología y cómo pensaban utilizarla sus clientes. Muchos lo enfocaron como la incorporación de funcionalidades que se añadían a sus propios sistemas de red: SNA, DECNet, Netware, NetBios. El Departamento de Defensa norteamericano hizo obligatorio el uso de TCP/IP en buena parte de sus adquisiciones de software pero dio pocas indicaciones a los suministradores sobre cómo desarrollar productos TCP/IP realmente útiles.
En 1985, reconociendo la falta de información y formación adecuadas, Dan Lynch, en cooperación con el IAB, organizó una reunión de tres días para todos los fabricantes que quisieran saber cómo trabajaba TCP/IP y qué es lo que aún no era capaz de hacer. Los ponentes pertenecían fundamentalmente a la comunidad investigadora de DARPA que había desarrollado los protocolos y los utilizaba en su trabajo diario. Alrededor de 250 fabricantes acudieron a escuchar a unos 50 inventores y experimentadores. Los resultados fueron una sorpresa para ambas partes: los fabricantes descubrieron con asombro que los inventores estaban abiertos a sugerencias sobre cómo funcionaban los sistemas (y sobre qué era lo que aún no eran capaces de hacer) y los inventores recibieron con agrado información sobre nuevos problemas que no conocían pero que habían encontrado los fabricantes en el desarrollo y operación de nuevos productos. Así, quedó establecida un diálogo que ha durado más de una década.
Después de dos años de conferencias, cursos, reuniones de diseño y congresos, se organizó un acontecimiento especial para que los fabricantes cuyos productos funcionaran correctamente bajo TCP/IP pudieran mostrarlos conjuntamente durante tres días y demostraran lo bien que podían trabajar y correr en Internet. El primer "Interop trade show" nació en Septiembre de 1988. Cincuenta compañías presentaron sus productos y unos 5.000 ingenieros de organizaciones potencialmente compradoras acudieron a ver si todo funcionaba como se prometía. Y lo hizo. ¿Por qué? Porque los fabricantes habían trabajado intensamente para asegurar que sus productos interoperaban correctamente entre sí -incluso con los de sus competidores. El Interop ha crecido enormemente desde entonces y hoy en día se realiza cada año en siete lugares del mundo con una audiencia de 250.000 personas que acuden para comprobar qué productos interoperan correctamente con los demás, conocer cuáles son los últimos y para hablar sobre la tecnología más reciente.
La comercialización de Internet llevaba acarreada no sólo el desarrollo de servicios de red privados y competitivos sino también el de productos comerciales que implementen la tecnología Internet. A principios de los años 80 docenas de fabricantes incorporaron TCP/IP a sus productos debido a la aproximación de sus clientes a esta tecnología de redes. Desafortunadamente, carecían de información fiable sobre cómo funcionaba esta tecnología y cómo pensaban utilizarla sus clientes. Muchos lo enfocaron como la incorporación de funcionalidades que se añadían a sus propios sistemas de red: SNA, DECNet, Netware, NetBios. El Departamento de Defensa norteamericano hizo obligatorio el uso de TCP/IP en buena parte de sus adquisiciones de software pero dio pocas indicaciones a los suministradores sobre cómo desarrollar productos TCP/IP realmente útiles.
En 1985, reconociendo la falta de información y formación adecuadas, Dan Lynch, en cooperación con el IAB, organizó una reunión de tres días para todos los fabricantes que quisieran saber cómo trabajaba TCP/IP y qué es lo que aún no era capaz de hacer. Los ponentes pertenecían fundamentalmente a la comunidad investigadora de DARPA que había desarrollado los protocolos y los utilizaba en su trabajo diario. Alrededor de 250 fabricantes acudieron a escuchar a unos 50 inventores y experimentadores. Los resultados fueron una sorpresa para ambas partes: los fabricantes descubrieron con asombro que los inventores estaban abiertos a sugerencias sobre cómo funcionaban los sistemas (y sobre qué era lo que aún no eran capaces de hacer) y los inventores recibieron con agrado información sobre nuevos problemas que no conocían pero que habían encontrado los fabricantes en el desarrollo y operación de nuevos productos. Así, quedó establecida un diálogo que ha durado más de una década.
Después de dos años de conferencias, cursos, reuniones de diseño y congresos, se organizó un acontecimiento especial para que los fabricantes cuyos productos funcionaran correctamente bajo TCP/IP pudieran mostrarlos conjuntamente durante tres días y demostraran lo bien que podían trabajar y correr en Internet. El primer "Interop trade show" nació en Septiembre de 1988. Cincuenta compañías presentaron sus productos y unos 5.000 ingenieros de organizaciones potencialmente compradoras acudieron a ver si todo funcionaba como se prometía. Y lo hizo. ¿Por qué? Porque los fabricantes habían trabajado intensamente para asegurar que sus productos interoperaban correctamente entre sí -incluso con los de sus competidores. El Interop ha crecido enormemente desde entonces y hoy en día se realiza cada año en siete lugares del mundo con una audiencia de 250.000 personas que acuden para comprobar qué productos interoperan correctamente con los demás, conocer cuáles son los últimos y para hablar sobre la tecnología más reciente.
 En paralelo con los esfuerzos de comercialización amparados por las actividades del Interop, los fabricantes comenzaron a acudir a las reuniones de la IETF que se convocaban tres o cuatro veces al año para discutir nuevas ideas para extender el conjunto de protocolos relacionados con TCP/IP. Comenzaron con unos cientos de asistentes procedentes en su mayor parte del mundo académico y financiados por el sector público; actualmente estas reuniones atraen a varios miles de participantes, en su mayor parte del sector privado y financiados por éste. Los miembros de este grupo han hecho evolucionar el TCP/IP cooperando entre sí. La razón de que estas reuniones sean tan útiles es que acuden a ellas todas las partes implicadas: investigadores, usuarios finales y fabricantes.
La gestión de redes nos da un ejemplo de la beneficiosa relación entre la comunidad investigadora y los fabricantes. En los comienzos de Internet, se hacía hincapié en la definición e implementación de protocolos que alcanzaran la interoperación. A medida que crecía la red aparecieron situaciones en las que procedimientos desarrollados "ad hoc" para gestionar la red no eran capaces de crecer con ella. La configuración manual de tablas fue sustituida por algoritmos distribuidos automatizados y aparecieron nuevas herramientas para resolver problemas puntuales. En 1987 quedó claro que era necesario un protocolo que permitiera que se pudieran gestionar remota y uniformemente los elementos de una red, como los routers. Se propusieron varios protocolos con este propósito, entre ellos el SNMP (Single Network Management Protocol, protocolo simple de gestión de red) diseñado, como su propio nombre indica, buscando la simplicidad; HEMS, un diseño más complejo de la comunidad investigadora; y CMIP, desarrollado por la comunidad OSI. Una serie de reuniones llevaron a tomar la decisión de desestimar HEMS como candidato para la estandarización, dejando que tanto SNMP como CMIP siguieran adelante con la idea que el primero fuera una solución inmediata mientras que CMIP pasara a ser una aproximación a largo plazo: el mercado podría elegir el que resultara más apropiado. Hoy SNMP se usa casi universalmente para la gestión de red.
En los últimos años hemos vivido una nueva fase en la comercialización. Originalmente, los esfuerzos invertidos en esta tarea consistían fundamentalmente en fabricantes que ofrecían productos básicos para trabajar en la red y proveedores de servicio que ofrecían conectividad y servicios básicos. Internet se ha acabado convirtiendo en una "commodity", un servicio de disponibilidad generalizada para usuarios finales, y buena parte de la atención se ha centrado en el uso de la GII (Global Information Infraestructure) para el soporte de servicios comerciales. Este hecho se ha acelerado tremendamente por la rápida y amplia adopción de visualizadores y de la tecnología del World Wide Web, permitiendo a los usuarios acceder fácilmente a información distribuida a través del mundo. Están disponibles productos que facilitan el acceso a esta información y buena parte de los últimos desarrollos tecnológicos están dirigidos a obtener servicios de información cada vez más sofisticados sobre comunicaciones de datos básicas de Internet.
Continuar leyendo
En paralelo con los esfuerzos de comercialización amparados por las actividades del Interop, los fabricantes comenzaron a acudir a las reuniones de la IETF que se convocaban tres o cuatro veces al año para discutir nuevas ideas para extender el conjunto de protocolos relacionados con TCP/IP. Comenzaron con unos cientos de asistentes procedentes en su mayor parte del mundo académico y financiados por el sector público; actualmente estas reuniones atraen a varios miles de participantes, en su mayor parte del sector privado y financiados por éste. Los miembros de este grupo han hecho evolucionar el TCP/IP cooperando entre sí. La razón de que estas reuniones sean tan útiles es que acuden a ellas todas las partes implicadas: investigadores, usuarios finales y fabricantes.
La gestión de redes nos da un ejemplo de la beneficiosa relación entre la comunidad investigadora y los fabricantes. En los comienzos de Internet, se hacía hincapié en la definición e implementación de protocolos que alcanzaran la interoperación. A medida que crecía la red aparecieron situaciones en las que procedimientos desarrollados "ad hoc" para gestionar la red no eran capaces de crecer con ella. La configuración manual de tablas fue sustituida por algoritmos distribuidos automatizados y aparecieron nuevas herramientas para resolver problemas puntuales. En 1987 quedó claro que era necesario un protocolo que permitiera que se pudieran gestionar remota y uniformemente los elementos de una red, como los routers. Se propusieron varios protocolos con este propósito, entre ellos el SNMP (Single Network Management Protocol, protocolo simple de gestión de red) diseñado, como su propio nombre indica, buscando la simplicidad; HEMS, un diseño más complejo de la comunidad investigadora; y CMIP, desarrollado por la comunidad OSI. Una serie de reuniones llevaron a tomar la decisión de desestimar HEMS como candidato para la estandarización, dejando que tanto SNMP como CMIP siguieran adelante con la idea que el primero fuera una solución inmediata mientras que CMIP pasara a ser una aproximación a largo plazo: el mercado podría elegir el que resultara más apropiado. Hoy SNMP se usa casi universalmente para la gestión de red.
En los últimos años hemos vivido una nueva fase en la comercialización. Originalmente, los esfuerzos invertidos en esta tarea consistían fundamentalmente en fabricantes que ofrecían productos básicos para trabajar en la red y proveedores de servicio que ofrecían conectividad y servicios básicos. Internet se ha acabado convirtiendo en una "commodity", un servicio de disponibilidad generalizada para usuarios finales, y buena parte de la atención se ha centrado en el uso de la GII (Global Information Infraestructure) para el soporte de servicios comerciales. Este hecho se ha acelerado tremendamente por la rápida y amplia adopción de visualizadores y de la tecnología del World Wide Web, permitiendo a los usuarios acceder fácilmente a información distribuida a través del mundo. Están disponibles productos que facilitan el acceso a esta información y buena parte de los últimos desarrollos tecnológicos están dirigidos a obtener servicios de información cada vez más sofisticados sobre comunicaciones de datos básicas de Internet.
Continuar leyendo
jueves, 27 de marzo de 2008
 Internet es tanto un conjunto de comunidades como un conjunto de tecnologías y su éxito se puede atribuir tanto a la satisfacción de las necesidades básicas de la comunidad como a la utilización de esta comunidad de un modo efectivo para impulsar la infraestructura. El espíritu comunitario tiene una larga historia, empezando por la temprana ARPANET. Los investigadores de ésta red trabajaban como una comunidad cerrada para llevar a cabo las demostraciones iniciales de la tecnología de conmutación de paquetes descrita en la primera parte de este artículo.
Del mismo modo, la Paquetería por Satélite, la Paquetería por Radio y varios otros programas de investigación informática de la DARPA fueron actividades cooperativas y de contrato múltiple que, aún con dificultades, usaban cualquiera de los mecanismos disponibles para coordinar sus esfuerzos, empezando por el correo electrónico y siguiendo por la compartición de ficheros, acceso remoto y finalmente las prestaciones de la World Wide Web.
Cada uno de estos programas formaban un grupo de trabajo, empezando por el ARPANET Network Working Group (Grupo de Trabajo de la Red ARPANET). Dado que el único papel que ARPANET representaba era actuar como soporte de la infraestructura de los diversos programas de investigación, cuando Internet empezó a evolucionar, el Grupo de Trabajo de la Red se transformó en Grupo de Trabajo de Internet.
Internet es tanto un conjunto de comunidades como un conjunto de tecnologías y su éxito se puede atribuir tanto a la satisfacción de las necesidades básicas de la comunidad como a la utilización de esta comunidad de un modo efectivo para impulsar la infraestructura. El espíritu comunitario tiene una larga historia, empezando por la temprana ARPANET. Los investigadores de ésta red trabajaban como una comunidad cerrada para llevar a cabo las demostraciones iniciales de la tecnología de conmutación de paquetes descrita en la primera parte de este artículo.
Del mismo modo, la Paquetería por Satélite, la Paquetería por Radio y varios otros programas de investigación informática de la DARPA fueron actividades cooperativas y de contrato múltiple que, aún con dificultades, usaban cualquiera de los mecanismos disponibles para coordinar sus esfuerzos, empezando por el correo electrónico y siguiendo por la compartición de ficheros, acceso remoto y finalmente las prestaciones de la World Wide Web.
Cada uno de estos programas formaban un grupo de trabajo, empezando por el ARPANET Network Working Group (Grupo de Trabajo de la Red ARPANET). Dado que el único papel que ARPANET representaba era actuar como soporte de la infraestructura de los diversos programas de investigación, cuando Internet empezó a evolucionar, el Grupo de Trabajo de la Red se transformó en Grupo de Trabajo de Internet.
 A finales de los 70, como reconocimiento de que el crecimiento de Internet estaba siendo acompañado por un incremento en el tamaño de la comunidad investigadora interesada y, por tanto, generando una necesidad creciente de mecanismos de coordinación, Vinton Cerf, por entonces director del programa de Internet en DARPA, formó varios grupos de coordinación: el ICB (International Cooperation Board, Consejo de Cooperación Internacional) presidido por Peter Kirstein, para coordinar las actividades con los países cooperantes europeos y dedicado a la investigación en Paquetería por Satélite; el Internet Research Group (Grupo de Investigación en Internet), que fue un grupo inclusivo para proporcionar un entorno para el intercambio general de información; y el ICCB (Internet Configuration Control Board , Consejo de Control de la Configuración de Internet), presidido por Clark. El ICCB fue un grupo al que se pertenecía por invitación para asistir a Cerf en la dirección de la actividad incipiente de Internet.
En 1983, cuando Barry Leiner asumió la dirección del programa de investigación en DARPA, él y Clark observaron que el continuo crecimiento de la comunidad de Internet demandaba la reestructuración de los mecanismos de coordinación. El ICCB fue disuelto y sustituido por una estructura de equipos de trabajo, cada uno de ellos enfocado a un área específica de la tecnología, tal como los routers (encaminadores) o los protocolos extremo a extremo. Se creó el IAB (Internet Architecture Board, Consejo de la Arquitectura de Internet) incluyendo a los presidentes de los equipos de trabajo. Era, desde luego, solamente una coincidencia que los presidentes de los equipos de trabajo fueran las mismas personas que constituían el antiguo ICCB, y Clark continuó actuando como presidente.
Después de algunos cambios en la composición del IAB, Phill Gross fue nombrado presidente del revitalizado IETF (Internet Engineering Task Force, Equipo de Trabajo de Ingeniería de Internet), que en aquel momento era meramente un equipo de trabajo del IAB. Como mencionamos con anterioridad, en 1985 se produjo un tremendo crecimiento en el aspecto más práctico de la ingeniería de Internet. Tal crecimiento desembocó en una explosión en la asistencia a las reuniones del IETF y Gross se vio obligado a crear una subestructura en el IETF en forma de grupos de trabajo.
El crecimiento de Internet fue complementado por una gran expansión de la comunidad de usuarios. DARPA dejó de ser el único protagonista en la financiación de Internet. Además de NSFNET y de varias actividades financiadas por los gobiernos de Estados Unidos y otros países, el interés de parte del mundo empresarial había empezado a crecer. También en 1985, Kahn y Leiner abandonaron DARPA, y ello supuso un descenso significativo de la actividad de Internet allí. Como consecuencia, el IAB perdió a su principal espónsor y poco a poco fue asumiendo el liderazgo.
A finales de los 70, como reconocimiento de que el crecimiento de Internet estaba siendo acompañado por un incremento en el tamaño de la comunidad investigadora interesada y, por tanto, generando una necesidad creciente de mecanismos de coordinación, Vinton Cerf, por entonces director del programa de Internet en DARPA, formó varios grupos de coordinación: el ICB (International Cooperation Board, Consejo de Cooperación Internacional) presidido por Peter Kirstein, para coordinar las actividades con los países cooperantes europeos y dedicado a la investigación en Paquetería por Satélite; el Internet Research Group (Grupo de Investigación en Internet), que fue un grupo inclusivo para proporcionar un entorno para el intercambio general de información; y el ICCB (Internet Configuration Control Board , Consejo de Control de la Configuración de Internet), presidido por Clark. El ICCB fue un grupo al que se pertenecía por invitación para asistir a Cerf en la dirección de la actividad incipiente de Internet.
En 1983, cuando Barry Leiner asumió la dirección del programa de investigación en DARPA, él y Clark observaron que el continuo crecimiento de la comunidad de Internet demandaba la reestructuración de los mecanismos de coordinación. El ICCB fue disuelto y sustituido por una estructura de equipos de trabajo, cada uno de ellos enfocado a un área específica de la tecnología, tal como los routers (encaminadores) o los protocolos extremo a extremo. Se creó el IAB (Internet Architecture Board, Consejo de la Arquitectura de Internet) incluyendo a los presidentes de los equipos de trabajo. Era, desde luego, solamente una coincidencia que los presidentes de los equipos de trabajo fueran las mismas personas que constituían el antiguo ICCB, y Clark continuó actuando como presidente.
Después de algunos cambios en la composición del IAB, Phill Gross fue nombrado presidente del revitalizado IETF (Internet Engineering Task Force, Equipo de Trabajo de Ingeniería de Internet), que en aquel momento era meramente un equipo de trabajo del IAB. Como mencionamos con anterioridad, en 1985 se produjo un tremendo crecimiento en el aspecto más práctico de la ingeniería de Internet. Tal crecimiento desembocó en una explosión en la asistencia a las reuniones del IETF y Gross se vio obligado a crear una subestructura en el IETF en forma de grupos de trabajo.
El crecimiento de Internet fue complementado por una gran expansión de la comunidad de usuarios. DARPA dejó de ser el único protagonista en la financiación de Internet. Además de NSFNET y de varias actividades financiadas por los gobiernos de Estados Unidos y otros países, el interés de parte del mundo empresarial había empezado a crecer. También en 1985, Kahn y Leiner abandonaron DARPA, y ello supuso un descenso significativo de la actividad de Internet allí. Como consecuencia, el IAB perdió a su principal espónsor y poco a poco fue asumiendo el liderazgo.
 El crecimiento continuó y desembocó en una subestructura adicional tanto en el IAB como en el IETF. El IETF integró grupos de trabajo en áreas y designó directores de área. El IESG (Internet Engineering Steering Group, Grupo de Dirección de Ingeniería de Internet) se formó con estos directores de área. El IAB reconoció la importancia creciente del IETF y reestructuró el proceso de estándares para reconocer explícitamente al IESG como la principal entidad de revisión de estándares. El IAB también se reestructuró de manera que el resto de equipos de trabajo (aparte del IETF) se agruparon en el IRTF (Internet Research Task Force, Equipo de Trabajo de Investigación en Internet), presidido por Postel, mientras que los antiguos equipos de trabajo pasaron a llamarse "grupos de investigación".
El crecimiento en el mundo empresarial trajo como consecuencia un incremento de la preocupación por el propio proceso de estándares. Desde primeros de los años 80 hasta hoy, Internet creció y está creciendo más allá de sus raíces originales de investigación para incluir a una amplia comunidad de usuarios y una actividad comercial creciente. Se puso un mayor énfasis en hacer el proceso abierto y justo. Esto, junto a una necesidad reconocida de dar soporte a la comunidad de Internet, condujo a la formación de la Internet Society en 1991, bajo los auspicios de la CNRI (Corporation for National Research Initiatives, Corporación para las Iniciativas de Investigación Nacionales) de Kahn y el liderazgo de Cerf, junto al de la CNRI.
En 1992 todavía se realizó otra reorganización: El Internet Activities Board (Consejo de Actividades de Internet) fue reorganizado y sustituyó al Consejo de la Arquitectura de Internet, operando bajo los auspicios de la Internet Society. Se definió una relación más estrecha entre el nuevo IAB y el IESG, tomando el IETF y el propio IESG una responsabilidad mayor en la aprobación de estándares. Por último, se estableció una relación cooperativa y de soporte mutuo entre el IAB, el IETF y la Internet Society, tomando esta última como objetivo la provisión de servicio y otras medidas que facilitarían el trabajo del IETF.
El reciente desarrollo y amplia difusión del World Wide Web ha formado una nueva comunidad, pues muchos de los que trabajan en la WWW no se consideran a sí mismos como investigadores y desarrolladores primarios de la red. Se constituyó un nuevo organismo de coordinación, el W3C (World Wide Web Consortium). Liderado inicialmente desde el Laboratory for Computer Science del MIT por Tim Berners-Lee –el inventor del WWW- y Al Vezza, el W3C ha tomado bajo su responsabilidad la evolución de varios protocolos y estándares asociados con el web.
Así pues, a través de más de dos décadas de actividad en Internet, hemos asistido a la continua evolución de las estructuras organizativas designadas para dar soporte y facilitar a una comunidad en crecimiento el trabajo colaborativo en temas de Internet.
Continuar leyendo
El crecimiento continuó y desembocó en una subestructura adicional tanto en el IAB como en el IETF. El IETF integró grupos de trabajo en áreas y designó directores de área. El IESG (Internet Engineering Steering Group, Grupo de Dirección de Ingeniería de Internet) se formó con estos directores de área. El IAB reconoció la importancia creciente del IETF y reestructuró el proceso de estándares para reconocer explícitamente al IESG como la principal entidad de revisión de estándares. El IAB también se reestructuró de manera que el resto de equipos de trabajo (aparte del IETF) se agruparon en el IRTF (Internet Research Task Force, Equipo de Trabajo de Investigación en Internet), presidido por Postel, mientras que los antiguos equipos de trabajo pasaron a llamarse "grupos de investigación".
El crecimiento en el mundo empresarial trajo como consecuencia un incremento de la preocupación por el propio proceso de estándares. Desde primeros de los años 80 hasta hoy, Internet creció y está creciendo más allá de sus raíces originales de investigación para incluir a una amplia comunidad de usuarios y una actividad comercial creciente. Se puso un mayor énfasis en hacer el proceso abierto y justo. Esto, junto a una necesidad reconocida de dar soporte a la comunidad de Internet, condujo a la formación de la Internet Society en 1991, bajo los auspicios de la CNRI (Corporation for National Research Initiatives, Corporación para las Iniciativas de Investigación Nacionales) de Kahn y el liderazgo de Cerf, junto al de la CNRI.
En 1992 todavía se realizó otra reorganización: El Internet Activities Board (Consejo de Actividades de Internet) fue reorganizado y sustituyó al Consejo de la Arquitectura de Internet, operando bajo los auspicios de la Internet Society. Se definió una relación más estrecha entre el nuevo IAB y el IESG, tomando el IETF y el propio IESG una responsabilidad mayor en la aprobación de estándares. Por último, se estableció una relación cooperativa y de soporte mutuo entre el IAB, el IETF y la Internet Society, tomando esta última como objetivo la provisión de servicio y otras medidas que facilitarían el trabajo del IETF.
El reciente desarrollo y amplia difusión del World Wide Web ha formado una nueva comunidad, pues muchos de los que trabajan en la WWW no se consideran a sí mismos como investigadores y desarrolladores primarios de la red. Se constituyó un nuevo organismo de coordinación, el W3C (World Wide Web Consortium). Liderado inicialmente desde el Laboratory for Computer Science del MIT por Tim Berners-Lee –el inventor del WWW- y Al Vezza, el W3C ha tomado bajo su responsabilidad la evolución de varios protocolos y estándares asociados con el web.
Así pues, a través de más de dos décadas de actividad en Internet, hemos asistido a la continua evolución de las estructuras organizativas designadas para dar soporte y facilitar a una comunidad en crecimiento el trabajo colaborativo en temas de Internet.
Continuar leyendo
miércoles, 26 de marzo de 2008
 Un aspecto clave del rápido crecimiento de Internet ha sido el acceso libre y abierto a los documentos básicos, especialmente a las especificaciones de los protocolos.
Los comienzos de Arpanet y de Internet en la comunidad de investigación universitaria estimularon la tradición académica de la publicación abierta de ideas y resultados. Sin embargo, el ciclo normal de la publicación académica tradicional era demasiado formal y lento para el intercambio dinámico de ideas, esencial para crear redes.
En 1969 S.Crocker, entonces en UCLA, dio un paso clave al establecer la serie de notas RFC (Request For Comments, petición de comentarios). Estos memorándums pretendieron ser una vía informal y de distribución rápida para compartir ideas con otros investigadores en redes. Al principio, las RFC fueron impresas en papel y distribuidas vía correo "lento". Pero cuando el FTP (File Transfer Protocol, protocolo de transferencia de ficheros) empezó a usarse, las RFC se convirtieron en ficheros difundidos online a los que se accedía vía FTP. Hoy en día, desde luego, están disponibles en el World Wide Web en decenas de emplazamientos en todo el mundo. SRI, en su papel como Centro de Información en la Red, mantenía los directorios online. Jon Postel actuaba como editor de RFC y como gestor de la administración centralizada de la asignación de los números de protocolo requeridos, tareas en las que continúa hoy en día.
El efecto de las RFC era crear un bucle positivo de realimentación, con ideas o propuestas presentadas a base de que una RFC impulsara otra RFC con ideas adicionales y así sucesivamente. Una vez se hubiera obtenido un consenso se prepararía un documento de especificación. Tal especificación seria entonces usada como la base para las implementaciones por parte de los equipos de investigación.
Con el paso del tiempo, las RFC se han enfocado a estándares de protocolo –las especificaciones oficiales- aunque hay todavía RFC informativas que describen enfoques alternativos o proporcionan información de soporte en temas de protocolos e ingeniería. Las RFC son vistas ahora como los documentos de registro dentro de la comunidad de estándares y de ingeniería en Internet.
El acceso abierto a las RFC –libre si se dispone de cualquier clase de conexión a Internet- promueve el crecimiento de Internet porque permite que las especificaciones sean usadas a modo de ejemplo en las aulas universitarias o por emprendedores al desarrollar nuevos sistemas.
Un aspecto clave del rápido crecimiento de Internet ha sido el acceso libre y abierto a los documentos básicos, especialmente a las especificaciones de los protocolos.
Los comienzos de Arpanet y de Internet en la comunidad de investigación universitaria estimularon la tradición académica de la publicación abierta de ideas y resultados. Sin embargo, el ciclo normal de la publicación académica tradicional era demasiado formal y lento para el intercambio dinámico de ideas, esencial para crear redes.
En 1969 S.Crocker, entonces en UCLA, dio un paso clave al establecer la serie de notas RFC (Request For Comments, petición de comentarios). Estos memorándums pretendieron ser una vía informal y de distribución rápida para compartir ideas con otros investigadores en redes. Al principio, las RFC fueron impresas en papel y distribuidas vía correo "lento". Pero cuando el FTP (File Transfer Protocol, protocolo de transferencia de ficheros) empezó a usarse, las RFC se convirtieron en ficheros difundidos online a los que se accedía vía FTP. Hoy en día, desde luego, están disponibles en el World Wide Web en decenas de emplazamientos en todo el mundo. SRI, en su papel como Centro de Información en la Red, mantenía los directorios online. Jon Postel actuaba como editor de RFC y como gestor de la administración centralizada de la asignación de los números de protocolo requeridos, tareas en las que continúa hoy en día.
El efecto de las RFC era crear un bucle positivo de realimentación, con ideas o propuestas presentadas a base de que una RFC impulsara otra RFC con ideas adicionales y así sucesivamente. Una vez se hubiera obtenido un consenso se prepararía un documento de especificación. Tal especificación seria entonces usada como la base para las implementaciones por parte de los equipos de investigación.
Con el paso del tiempo, las RFC se han enfocado a estándares de protocolo –las especificaciones oficiales- aunque hay todavía RFC informativas que describen enfoques alternativos o proporcionan información de soporte en temas de protocolos e ingeniería. Las RFC son vistas ahora como los documentos de registro dentro de la comunidad de estándares y de ingeniería en Internet.
El acceso abierto a las RFC –libre si se dispone de cualquier clase de conexión a Internet- promueve el crecimiento de Internet porque permite que las especificaciones sean usadas a modo de ejemplo en las aulas universitarias o por emprendedores al desarrollar nuevos sistemas.
 El e-mail o correo electrónico ha supuesto un factor determinante en todas las áreas de Internet, lo que es particularmente cierto en el desarrollo de las especificaciones de protocolos, estándares técnicos e ingeniería en Internet. Las primitivas RFC a menudo presentaban al resto de la comunidad un conjunto de ideas desarrolladas por investigadores de un solo lugar. Después de empezar a usarse el correo electrónico, el modelo de autoría cambió: las RFC pasaron a ser presentadas por coautores con visiones en común, independientemente de su localización.
Las listas de correo especializadas ha sido usadas ampliamente en el desarrollo de la especificación de protocolos, y continúan siendo una herramienta importante. El IETF tiene ahora más de 75 grupos de trabajo, cada uno dedicado a un aspecto distinto de la ingeniería en Internet. Cada uno de estos grupos de trabajo dispone de una lista de correo para discutir uno o más borradores bajo desarrollo. Cuando se alcanza el consenso en el documento, éste puede ser distribuido como una RFC.
Debido a que la rápida expansión actual de Internet se alimenta por el aprovechamiento de su capacidad de promover la compartición de información, deberíamos entender que el primer papel en esta tarea consistió en compartir la información acerca de su propio diseño y operación a través de los documentos RFC. Este método único de producir nuevas capacidades en la red continuará siendo crítico para la futura evolución de Internet.
Continuar leyendo
El e-mail o correo electrónico ha supuesto un factor determinante en todas las áreas de Internet, lo que es particularmente cierto en el desarrollo de las especificaciones de protocolos, estándares técnicos e ingeniería en Internet. Las primitivas RFC a menudo presentaban al resto de la comunidad un conjunto de ideas desarrolladas por investigadores de un solo lugar. Después de empezar a usarse el correo electrónico, el modelo de autoría cambió: las RFC pasaron a ser presentadas por coautores con visiones en común, independientemente de su localización.
Las listas de correo especializadas ha sido usadas ampliamente en el desarrollo de la especificación de protocolos, y continúan siendo una herramienta importante. El IETF tiene ahora más de 75 grupos de trabajo, cada uno dedicado a un aspecto distinto de la ingeniería en Internet. Cada uno de estos grupos de trabajo dispone de una lista de correo para discutir uno o más borradores bajo desarrollo. Cuando se alcanza el consenso en el documento, éste puede ser distribuido como una RFC.
Debido a que la rápida expansión actual de Internet se alimenta por el aprovechamiento de su capacidad de promover la compartición de información, deberíamos entender que el primer papel en esta tarea consistió en compartir la información acerca de su propio diseño y operación a través de los documentos RFC. Este método único de producir nuevas capacidades en la red continuará siendo crítico para la futura evolución de Internet.
Continuar leyendo
martes, 25 de marzo de 2008
 Al mismo tiempo que la tecnología Internet estaba siendo validada experimentalmente y usada ampliamente entre un grupo de investigadores de informática se estaban desarrollando otras redes y tecnologías. La utilidad de las redes de ordenadores (especialmente el correo electrónico utilizado por los contratistas de DARPA y el Departamento de Defensa en ARPANET) siguió siendo evidente para otras comunidades y disciplinas de forma que a mediados de los años 70 las redes de ordenadores comenzaron a difundirse allá donde se podía encontrar financiación para las mismas. El Departamento norteamericano de Energía (DoE, Deparment of Energy) estableció MFENet para sus investigadores que trabajaban sobre energía de fusión, mientras que los físicos de altas energías fueron los encargados de construir HEPNet. Los físicos de la NASA continuaron con SPAN y Rick Adrion, David Farber y Larry Landweber fundaron CSNET para la comunidad informática académica y de la industria con la financiación inicial de la NFS (National Science Foundation, Fundación Nacional de la Ciencia) de Estados Unidos. La libre diseminación del sistema operativo Unix de ATT dio lugar a USENET, basada en los protocolos de comunicación UUCP de Unix, y en 1981 Greydon Freeman e Ira Fuchs diseñaron BITNET, que unía los ordenadores centrales del mundo académico siguiendo el paradigma de correo electrónico como "postales". Con la excepción de BITNET y USENET, todas las primeras redes (como ARPANET) se construyeron para un propósito determinado. Es decir, estaban dedicadas (y restringidas) a comunidades cerradas de estudiosos; de ahí las escasas presiones por hacer estas redes compatibles y, en consecuencia, el hecho de que durante mucho tiempo no lo fueran. Además, estaban empezando a proponerse tecnologías alternativas en el sector comercial, como XNS de Xerox, DECNet, y la SNA de IBM (8). Sólo restaba que los programas ingleses JANET (1984) y norteamericano NSFNET (1985) anunciaran explícitamente que su propósito era servir a toda la comunidad de la enseñanza superior sin importar su disciplina. De hecho, una de las condiciones para que una universidad norteamericana recibiera financiación de la NSF para conectarse a Internet era que "la conexión estuviera disponible para todos los usuarios cualificados del campus".
Al mismo tiempo que la tecnología Internet estaba siendo validada experimentalmente y usada ampliamente entre un grupo de investigadores de informática se estaban desarrollando otras redes y tecnologías. La utilidad de las redes de ordenadores (especialmente el correo electrónico utilizado por los contratistas de DARPA y el Departamento de Defensa en ARPANET) siguió siendo evidente para otras comunidades y disciplinas de forma que a mediados de los años 70 las redes de ordenadores comenzaron a difundirse allá donde se podía encontrar financiación para las mismas. El Departamento norteamericano de Energía (DoE, Deparment of Energy) estableció MFENet para sus investigadores que trabajaban sobre energía de fusión, mientras que los físicos de altas energías fueron los encargados de construir HEPNet. Los físicos de la NASA continuaron con SPAN y Rick Adrion, David Farber y Larry Landweber fundaron CSNET para la comunidad informática académica y de la industria con la financiación inicial de la NFS (National Science Foundation, Fundación Nacional de la Ciencia) de Estados Unidos. La libre diseminación del sistema operativo Unix de ATT dio lugar a USENET, basada en los protocolos de comunicación UUCP de Unix, y en 1981 Greydon Freeman e Ira Fuchs diseñaron BITNET, que unía los ordenadores centrales del mundo académico siguiendo el paradigma de correo electrónico como "postales". Con la excepción de BITNET y USENET, todas las primeras redes (como ARPANET) se construyeron para un propósito determinado. Es decir, estaban dedicadas (y restringidas) a comunidades cerradas de estudiosos; de ahí las escasas presiones por hacer estas redes compatibles y, en consecuencia, el hecho de que durante mucho tiempo no lo fueran. Además, estaban empezando a proponerse tecnologías alternativas en el sector comercial, como XNS de Xerox, DECNet, y la SNA de IBM (8). Sólo restaba que los programas ingleses JANET (1984) y norteamericano NSFNET (1985) anunciaran explícitamente que su propósito era servir a toda la comunidad de la enseñanza superior sin importar su disciplina. De hecho, una de las condiciones para que una universidad norteamericana recibiera financiación de la NSF para conectarse a Internet era que "la conexión estuviera disponible para todos los usuarios cualificados del campus".
 En 1985 Dennins Jenning acudió desde Irlanda para pasar un año en NFS dirigiendo el programa NSFNET. Trabajó con el resto de la comunidad para ayudar a la NSF a tomar una decisión crítica: si TCP/IP debería ser obligatorio en el programa NSFNET. Cuando Steve Wolff llegó al programa NFSNET en 1986 reconoció la necesidad de una infraestructura de red amplia que pudiera ser de ayuda a la comunidad investigadora y a la académica en general, junto a la necesidad de desarrollar una estrategia para establecer esta infraestructura sobre bases independientes de la financiación pública directa. Se adoptaron varias políticas y estrategias para alcanzar estos fines.
La NSF optó también por mantener la infraestructura organizativa de Internet existente (DARPA) dispuesta jerárquicamente bajo el IAB (Internet Activities Board, Comité de Actividades de Internet). La declaración pública de esta decisión firmada por todos sus autores (por los grupos de Arquitectura e Ingeniería de la IAB, y por el NTAG de la NSF) apareció como la RFC 985 ("Requisitos para pasarelas de Internet") que formalmente aseguraba la interoperatividad entre las partes de Internet dependientes de DARPA y de NSF.
Junto a la selección de TCP/IP para el programa NSFNET, las agencias federales norteamericanas idearon y pusieron en práctica otras decisiones que llevaron a la Internet de hoy:
En 1985 Dennins Jenning acudió desde Irlanda para pasar un año en NFS dirigiendo el programa NSFNET. Trabajó con el resto de la comunidad para ayudar a la NSF a tomar una decisión crítica: si TCP/IP debería ser obligatorio en el programa NSFNET. Cuando Steve Wolff llegó al programa NFSNET en 1986 reconoció la necesidad de una infraestructura de red amplia que pudiera ser de ayuda a la comunidad investigadora y a la académica en general, junto a la necesidad de desarrollar una estrategia para establecer esta infraestructura sobre bases independientes de la financiación pública directa. Se adoptaron varias políticas y estrategias para alcanzar estos fines.
La NSF optó también por mantener la infraestructura organizativa de Internet existente (DARPA) dispuesta jerárquicamente bajo el IAB (Internet Activities Board, Comité de Actividades de Internet). La declaración pública de esta decisión firmada por todos sus autores (por los grupos de Arquitectura e Ingeniería de la IAB, y por el NTAG de la NSF) apareció como la RFC 985 ("Requisitos para pasarelas de Internet") que formalmente aseguraba la interoperatividad entre las partes de Internet dependientes de DARPA y de NSF.
Junto a la selección de TCP/IP para el programa NSFNET, las agencias federales norteamericanas idearon y pusieron en práctica otras decisiones que llevaron a la Internet de hoy:
- Las agencias federales compartían el coste de la infraestructura común, como los circuitos transoceánicos. También mantenían la gestión de puntos de interconexión para el tráfico entre agencias: los "Federal Internet Exchanges" (FIX-E y FIX-W) que se desarrollaron con este propósito sirvieron de modelo para los puntos de acceso a red y los sistemas *IX que son unas de las funcionalidades más destacadas de la arquitectura de la Internet actual.
- Para coordinar estas actividades se formó el FNC (Federal Networking Council, Consejo Federal de Redes). El FNC cooperaba también con otras organizaciones internacionales, como RARE en Europa, a través del CCIRN (Coordinating Committee on Intercontinental Research Networking, Comité de Coordinación Intercontinental de Investigación sobre Redes) para coordinar el apoyo a Internet de la comunidad investigadora mundial.
- Esta cooperación entre agencias en temas relacionados con Internet tiene una larga historia. En 1981, un acuerdo sin precedentes entre Farber, actuando en nombre de CSNET y NSF, y Kahn por DARPA, permitió que el tráfico de CSNET compartiera la infraestructura de ARPANET de acuerdo según parámetros estadísticos.
- En consecuencia, y de forma similar, la NFS promocionó sus redes regionales de NSFNET, inicialmente académicas, para buscar clientes comerciales, expandiendo sus servicios y explotando las economías de escala resultantes para reducir los costes de suscripción para todos.
- En el backbone NFSNET (el segmento que cruza los EE.UU.) NSF estableció una política aceptable de uso (AUP, Acceptable Use Policy) que prohibía el uso del backbone para fines "que no fueran de apoyo a la Investigación y la Educación". El predecible e intencionado resultado de promocionar el tráfico comercial en la red a niveles locales y regionales era estimular la aparición y/o crecimiento de grandes redes privadas y competitivas como PSI, UUNET, ANS CO+RE, y, posteriormente, otras. Este proceso de aumento de la financiación privada para el uso comercial se resolvió tras largas discusiones que empezaron en 1988 con una serie de conferencias patrocinadas por NSF en la Kennedy School of Government de la Universidad de Harvard, bajo el lema "La comercialización y privatización de Internet", complementadas por la lista "com-priv" de la propia red.
- En 1988 un comité del National Research Council (Consejo Nacional de Investigación), presidido por Kleinrock y entre cuyos miembros estaban Clark y Kahn, elaboró un informe dirigido a la NSF y titulado "Towards a National Research Network". El informe llamó la atención del entonces senador Al Gore (N. del T.: Vicepresidente de los EE.UU. desde 1992) le introdujo en las redes de alta velocidad que pusieron los cimientos de la futura «Autopista de la Información».
- La política de privatización de la NSF culminó en Abril de 1995 con la eliminación de la financiación del backbone NSFNET. Los fondos así recuperados fueron redistribuidos competitivamente entre redes regionales para comprar conectividad de ámbito nacional a Internet a las ahora numerosas redes privadas de larga distancia.
 El backbone había hecho la transición desde una red construida con routers de la comunidad investigadora (los routers Fuzzball de David Mills) a equipos comerciales. En su vida de ocho años y medio, el backbone había crecido desde seis nodos con enlaces de 56Kb a 21 nodos con enlaces múltiples de 45Mb.Había visto crecer Internet hasta alcanzar más de 50.000 redes en los cinco continentes y en el espacio exterior, con aproximadamente 29.000 redes en los Estados Unidos.
El efecto del ecumenismo del programa NSFNET y su financiación (200 millones de dólares entre 1986 y 1995) y de la calidad de los protocolos fue tal que en 1990, cuando la propia ARPANET se disolvió, TCP/IP había sustituido o marginado a la mayor parte de los restantes protocolos de grandes redes de ordenadores e IP estaba en camino de convertirse en el servicio portador de la llamada Infraestructura Global de Información.
Continuar leyendo
El backbone había hecho la transición desde una red construida con routers de la comunidad investigadora (los routers Fuzzball de David Mills) a equipos comerciales. En su vida de ocho años y medio, el backbone había crecido desde seis nodos con enlaces de 56Kb a 21 nodos con enlaces múltiples de 45Mb.Había visto crecer Internet hasta alcanzar más de 50.000 redes en los cinco continentes y en el espacio exterior, con aproximadamente 29.000 redes en los Estados Unidos.
El efecto del ecumenismo del programa NSFNET y su financiación (200 millones de dólares entre 1986 y 1995) y de la calidad de los protocolos fue tal que en 1990, cuando la propia ARPANET se disolvió, TCP/IP había sustituido o marginado a la mayor parte de los restantes protocolos de grandes redes de ordenadores e IP estaba en camino de convertirse en el servicio portador de la llamada Infraestructura Global de Información.
Continuar leyendo
lunes, 24 de marzo de 2008
 DARPA formalizó tres contratos con Stanford (Cerf), BBN (Ray Tomlinson) y UCLA (Peter Kirstein) para implementar TCP/IP (en el documento original de Cerf y Kahn se llamaba simplemente TCP pero contenía ambos componentes). El equipo de Stanford, dirigido por Cerf, produjo las especificaciones detalladas y al cabo de un año hubo tres implementaciones independientes de TCP que podían interoperar.
Este fue el principio de un largo periodo de experimentación y desarrollo para evolucionar y madurar el concepto y tecnología de Internet. Partiendo de las tres primeras redes ARPANET, radio y satélite y de sus comunidades de investigación iniciales, el entorno experimental creció hasta incorporar esencialmente cualquier forma de red y una amplia comunidad de investigación y desarrollo. Cada expansión afrontó nuevos desafíos.
Las primeras implementaciones de TCP se hicieron para grandes sistemas en tiempo compartido como Tenex y TOPS 20. Cuando aparecieron los ordenadores de sobremesa (desktop), TCP era demasiado grande y complejo como para funcionar en ordenadores personales. David Clark y su equipo de investigación del MIT empezaron a buscar la implementación de TCP más sencilla y compacta posible. La desarrollaron, primero para el Alto de Xerox (la primera estación de trabajo personal desarrollada en el PARC de Xerox), y luego para el PC de IBM. Esta implementación operaba con otras de TCP, pero estaba adaptada al conjunto de aplicaciones y a las prestaciones de un ordenador personal, y demostraba que las estaciones de trabajo, al igual que los grandes sistemas, podían ser parte de Internet.
DARPA formalizó tres contratos con Stanford (Cerf), BBN (Ray Tomlinson) y UCLA (Peter Kirstein) para implementar TCP/IP (en el documento original de Cerf y Kahn se llamaba simplemente TCP pero contenía ambos componentes). El equipo de Stanford, dirigido por Cerf, produjo las especificaciones detalladas y al cabo de un año hubo tres implementaciones independientes de TCP que podían interoperar.
Este fue el principio de un largo periodo de experimentación y desarrollo para evolucionar y madurar el concepto y tecnología de Internet. Partiendo de las tres primeras redes ARPANET, radio y satélite y de sus comunidades de investigación iniciales, el entorno experimental creció hasta incorporar esencialmente cualquier forma de red y una amplia comunidad de investigación y desarrollo. Cada expansión afrontó nuevos desafíos.
Las primeras implementaciones de TCP se hicieron para grandes sistemas en tiempo compartido como Tenex y TOPS 20. Cuando aparecieron los ordenadores de sobremesa (desktop), TCP era demasiado grande y complejo como para funcionar en ordenadores personales. David Clark y su equipo de investigación del MIT empezaron a buscar la implementación de TCP más sencilla y compacta posible. La desarrollaron, primero para el Alto de Xerox (la primera estación de trabajo personal desarrollada en el PARC de Xerox), y luego para el PC de IBM. Esta implementación operaba con otras de TCP, pero estaba adaptada al conjunto de aplicaciones y a las prestaciones de un ordenador personal, y demostraba que las estaciones de trabajo, al igual que los grandes sistemas, podían ser parte de Internet.
 En los años 80, el desarrollo de LAN, PC y estaciones de trabajo permitió que la naciente Internet floreciera. La tecnología Ethernet, desarrollada por Bob Metcalfe en el PARC de Xerox en 1973, es la dominante en Internet, y los PCs y las estaciones de trabajo los modelos de ordenador dominantes. El cambio que supone pasar de una pocas redes con un modesto número de hosts (el modelo original de ARPANET) a tener muchas redes dio lugar a nuevos conceptos y a cambios en la tecnología. En primer lugar, hubo que definir tres clases de redes (A, B y C) para acomodar todas las existentes. La clase A representa a las redes grandes, a escala nacional (pocas redes con muchos ordenadores); la clase B representa redes regionales; por último, la clase C representa redes de área local (muchas redes con relativamente pocos ordenadores).
Como resultado del crecimiento de Internet, se produjo un cambio de gran importancia para la red y su gestión. Para facilitar el uso de Internet por sus usuarios se asignaron nombres a los hosts de forma que resultara innecesario recordar sus direcciones numéricas. Originalmente había un número muy limitado de máquinas, por lo que bastaba con una simple tabla con todos los ordenadores y sus direcciones asociadas.
El cambio hacia un gran número de redes gestionadas independientemente (por ejemplo, las LAN) significó que no resultara ya fiable tener una pequeña tabla con todos los hosts. Esto llevó a la invención del DNS (Domain Name System, sistema de nombres de dominio) por Paul Mockapetris de USC/ISI. El DNS permitía un mecanismo escalable y distribuido para resolver jerárquicamente los nombres de los hosts (por ejemplo, www.acm.org o www.ati.es) en direcciones de Internet.
El incremento del tamaño de Internet resultó también un desafío para los routers. Originalmente había un sencillo algoritmo de enrutamiento que estaba implementado uniformemente en todos los routers de Internet. A medida que el número de redes en Internet se multiplicaba, el diseño inicial no era ya capaz de expandirse, por lo que fue sustituido por un modelo jerárquico de enrutamiento con un protocolo IGP (Interior Gateway Protocol, protocolo interno de pasarela) usado dentro de cada región de Internet y un protocolo EGP (Exterior Gateway Protocol, protocolo externo de pasarela) usado para mantener unidas las regiones. El diseño permitía que distintas regiones utilizaran IGP distintos, por lo que los requisitos de coste, velocidad de configuración, robustez y escalabilidad, podían ajustarse a cada situación. Los algoritmos de enrutamiento no eran los únicos en poner en dificultades la capacidad de los routers, también lo hacía el tamaño de la tablas de direccionamiento. Se presentaron nuevas aproximaciones a la agregación de direcciones (en particular CIDR, Classless Interdomain Routing, enrutamiento entre dominios sin clase) para controlar el tamaño de las tablas de enrutamiento.
En los años 80, el desarrollo de LAN, PC y estaciones de trabajo permitió que la naciente Internet floreciera. La tecnología Ethernet, desarrollada por Bob Metcalfe en el PARC de Xerox en 1973, es la dominante en Internet, y los PCs y las estaciones de trabajo los modelos de ordenador dominantes. El cambio que supone pasar de una pocas redes con un modesto número de hosts (el modelo original de ARPANET) a tener muchas redes dio lugar a nuevos conceptos y a cambios en la tecnología. En primer lugar, hubo que definir tres clases de redes (A, B y C) para acomodar todas las existentes. La clase A representa a las redes grandes, a escala nacional (pocas redes con muchos ordenadores); la clase B representa redes regionales; por último, la clase C representa redes de área local (muchas redes con relativamente pocos ordenadores).
Como resultado del crecimiento de Internet, se produjo un cambio de gran importancia para la red y su gestión. Para facilitar el uso de Internet por sus usuarios se asignaron nombres a los hosts de forma que resultara innecesario recordar sus direcciones numéricas. Originalmente había un número muy limitado de máquinas, por lo que bastaba con una simple tabla con todos los ordenadores y sus direcciones asociadas.
El cambio hacia un gran número de redes gestionadas independientemente (por ejemplo, las LAN) significó que no resultara ya fiable tener una pequeña tabla con todos los hosts. Esto llevó a la invención del DNS (Domain Name System, sistema de nombres de dominio) por Paul Mockapetris de USC/ISI. El DNS permitía un mecanismo escalable y distribuido para resolver jerárquicamente los nombres de los hosts (por ejemplo, www.acm.org o www.ati.es) en direcciones de Internet.
El incremento del tamaño de Internet resultó también un desafío para los routers. Originalmente había un sencillo algoritmo de enrutamiento que estaba implementado uniformemente en todos los routers de Internet. A medida que el número de redes en Internet se multiplicaba, el diseño inicial no era ya capaz de expandirse, por lo que fue sustituido por un modelo jerárquico de enrutamiento con un protocolo IGP (Interior Gateway Protocol, protocolo interno de pasarela) usado dentro de cada región de Internet y un protocolo EGP (Exterior Gateway Protocol, protocolo externo de pasarela) usado para mantener unidas las regiones. El diseño permitía que distintas regiones utilizaran IGP distintos, por lo que los requisitos de coste, velocidad de configuración, robustez y escalabilidad, podían ajustarse a cada situación. Los algoritmos de enrutamiento no eran los únicos en poner en dificultades la capacidad de los routers, también lo hacía el tamaño de la tablas de direccionamiento. Se presentaron nuevas aproximaciones a la agregación de direcciones (en particular CIDR, Classless Interdomain Routing, enrutamiento entre dominios sin clase) para controlar el tamaño de las tablas de enrutamiento.
 A medida que evolucionaba Internet, la propagación de los cambios en el software, especialmente el de los hosts, se fue convirtiendo en uno de sus mayores desafíos. DARPA financió a la Universidad de California en Berkeley en una investigación sobre modificaciones en el sistema operativo Unix, incorporando el TCP/IP desarrollado en BBN. Aunque posteriormente Berkeley modificó esta implementación del BBN para que operara de forma más eficiente con el sistema y el kernel de Unix, la incorporación de TCP/IP en el sistema Unix BSD demostró ser un elemento crítico en la difusión de los protocolos entre la comunidad investigadora. BSD empezó a ser utilizado en sus operaciones diarias por buena parte de la comunidad investigadora en temas relacionados con informática. Visto en perspectiva, la estrategia de incorporar los protocolos de Internet en un sistema operativo utilizado por la comunidad investigadora fue uno de los elementos clave en la exitosa y amplia aceptación de Internet.
Uno de los desafíos más interesantes fue la transición del protocolo para hosts de ARPANET desde NCP a TCP/IP el 1 de enero de 1983. Se trataba de una ocasión muy importante que exigía que todos los hosts se convirtieran simultáneamente o que permanecieran comunicados mediante mecanismos desarrollados para la ocasión. La transición fue cuidadosamente planificada dentro de la comunidad con varios años de antelación a la fecha, pero fue sorprendentemente sobre ruedas (a pesar de dar lugar a la distribución de insignias con la inscripción "Yo sobreviví a la transición a TCP/IP").
TCP/IP había sido adoptado como un estándar por el ejército norteamericano tres años antes, en 1980. Esto permitió al ejército empezar a compartir la tecnología DARPA basada en Internet y llevó a la separación final entre las comunidades militares y no militares. En 1983 ARPANET estaba siendo usada por un número significativo de organizaciones operativas y de investigación y desarrollo en el área de la defensa. La transición desde NCP a TCP/IP en ARPANET permitió la división en una MILNET para dar soporte a requisitos operativos y una ARPANET para las necesidades de investigación.
Así, en 1985, Internet estaba firmemente establecida como una tecnología que ayudaba a una amplia comunidad de investigadores y desarrolladores, y empezaba a ser empleada por otros grupos en sus comunicaciones diarias entre ordenadores. El correo electrónico se empleaba ampliamente entre varias comunidades, a menudo entre distintos sistemas. La interconexión entre los diversos sistemas de correo demostraba la utilidad de las comunicaciones electrónicas entre personas.
Continuar leyendo
A medida que evolucionaba Internet, la propagación de los cambios en el software, especialmente el de los hosts, se fue convirtiendo en uno de sus mayores desafíos. DARPA financió a la Universidad de California en Berkeley en una investigación sobre modificaciones en el sistema operativo Unix, incorporando el TCP/IP desarrollado en BBN. Aunque posteriormente Berkeley modificó esta implementación del BBN para que operara de forma más eficiente con el sistema y el kernel de Unix, la incorporación de TCP/IP en el sistema Unix BSD demostró ser un elemento crítico en la difusión de los protocolos entre la comunidad investigadora. BSD empezó a ser utilizado en sus operaciones diarias por buena parte de la comunidad investigadora en temas relacionados con informática. Visto en perspectiva, la estrategia de incorporar los protocolos de Internet en un sistema operativo utilizado por la comunidad investigadora fue uno de los elementos clave en la exitosa y amplia aceptación de Internet.
Uno de los desafíos más interesantes fue la transición del protocolo para hosts de ARPANET desde NCP a TCP/IP el 1 de enero de 1983. Se trataba de una ocasión muy importante que exigía que todos los hosts se convirtieran simultáneamente o que permanecieran comunicados mediante mecanismos desarrollados para la ocasión. La transición fue cuidadosamente planificada dentro de la comunidad con varios años de antelación a la fecha, pero fue sorprendentemente sobre ruedas (a pesar de dar lugar a la distribución de insignias con la inscripción "Yo sobreviví a la transición a TCP/IP").
TCP/IP había sido adoptado como un estándar por el ejército norteamericano tres años antes, en 1980. Esto permitió al ejército empezar a compartir la tecnología DARPA basada en Internet y llevó a la separación final entre las comunidades militares y no militares. En 1983 ARPANET estaba siendo usada por un número significativo de organizaciones operativas y de investigación y desarrollo en el área de la defensa. La transición desde NCP a TCP/IP en ARPANET permitió la división en una MILNET para dar soporte a requisitos operativos y una ARPANET para las necesidades de investigación.
Así, en 1985, Internet estaba firmemente establecida como una tecnología que ayudaba a una amplia comunidad de investigadores y desarrolladores, y empezaba a ser empleada por otros grupos en sus comunicaciones diarias entre ordenadores. El correo electrónico se empleaba ampliamente entre varias comunidades, a menudo entre distintos sistemas. La interconexión entre los diversos sistemas de correo demostraba la utilidad de las comunicaciones electrónicas entre personas.
Continuar leyendo
domingo, 23 de marzo de 2008
Cuatro fueron las reglas fundamentales en las primeras ideas de Kahn:
- Cada red distinta debería mantenerse por sí misma y no deberían requerirse cambios internos a ninguna de ellas para conectarse a Internet.
- Las comunicaciones deberían ser establecidas en base a la filosofía del "best-effort" (lo mejor posible). Si un paquete no llegara a su destino debería ser en breve retransmitido desde el emisor.
- Para interconectar redes se usarían cajas negras, las cuales más tarde serían denominadas gateways (pasarelas) y routers (enrutadores). Los gateways no deberían almacenar información alguna sobre los flujos individuales de paquetes que circulasen a través de ellos, manteniendo de esta manera su simplicidad y evitando la complicada adaptación y recuperación a partir de las diversas modalidades de fallo.
- No habría ningún control global a nivel de operaciones.
- Algoritmos para evitar la pérdida de paquetes en base a la invalidación de las comunicaciones y la reiniciación de las mismas para la retransmisión exitosa desde el emisor.
- Provisión de pipelining ("tuberías") host a host de tal forma que se pudieran enrutar múltiples paquetes desde el origen al destino a discreción de los hosts participantes, siempre que las redes intermedias lo permitieran.
- Funciones de pasarela para permitir redirigir los paquetes adecuadamente. Esto incluía la interpretación de las cabeceras IP para enrutado, manejo de interfaces y división de paquetes en trozos más pequeños si fuera necesario.
- La necesidad de controles (checksums) extremo a extremo, reensamblaje de paquetes a partir de fragmentos, y detección de duplicados si los hubiere.
- Necesidad de direccionamiento global.
- Técnicas para el control del flujo host a host.
- Interacción con varios sistemas operativos.
- Implementación eficiente y rendimiento de la red, aunque en principio éstas eran consideraciones secundarias.
 Kahn empezó a trabajar en un conjunto de principios para sistemas operativos orientados a comunicaciones mientras se encontraba en BBN y escribió algunas de sus primeras ideas en un memorándum interno de BBN titulado "Communications Principles for Operating Systems". En ese momento, se dió cuenta de que le sería necesario aprender los detalles de implementación de cada sistema operativo para tener la posibilidad de incluir nuevos protocolos de manera eficiente. Así, en la primavera de 1973, después de haber empezado el trabajo de "Internetting", le pidió a Vinton Cerf (entonces en la Universidad de Stanford) que trabajara con él en el diseño detallado del protocolo. Cerf había estado íntimamente implicado en el diseño y desarrollo original del NCP y ya tenía conocimientos sobre la construcción de interfaces con los sistemas operativos existentes. De esta forma, valiéndose del enfoque arquitectural de Kahn en cuanto a comunicaciones y de la experiencia en NCP de Cerf, se asociaron para abordar los detalles de lo que acabaría siendo TCP/IP.
El trabajo en común fue altamente productivo y la primera versión escrita bajo este enfoque fue distribuida en una sesión especial del INWG (International Network Working Group, Grupo de trabajo sobre redes internacionales) que había sido convocada con motivo de una conferencia de la Universidad de Sussex en Septiembre de 1973. Cerf había sido invitado a presidir el grupo y aprovechó la ocasión para celebrar una reunión de los miembros del INWG, ampliamente representados en esta conferencia de Sussex.
Estas son las directrices básicas que surgieron de la colaboración entre Kahn y Cerf:
Kahn empezó a trabajar en un conjunto de principios para sistemas operativos orientados a comunicaciones mientras se encontraba en BBN y escribió algunas de sus primeras ideas en un memorándum interno de BBN titulado "Communications Principles for Operating Systems". En ese momento, se dió cuenta de que le sería necesario aprender los detalles de implementación de cada sistema operativo para tener la posibilidad de incluir nuevos protocolos de manera eficiente. Así, en la primavera de 1973, después de haber empezado el trabajo de "Internetting", le pidió a Vinton Cerf (entonces en la Universidad de Stanford) que trabajara con él en el diseño detallado del protocolo. Cerf había estado íntimamente implicado en el diseño y desarrollo original del NCP y ya tenía conocimientos sobre la construcción de interfaces con los sistemas operativos existentes. De esta forma, valiéndose del enfoque arquitectural de Kahn en cuanto a comunicaciones y de la experiencia en NCP de Cerf, se asociaron para abordar los detalles de lo que acabaría siendo TCP/IP.
El trabajo en común fue altamente productivo y la primera versión escrita bajo este enfoque fue distribuida en una sesión especial del INWG (International Network Working Group, Grupo de trabajo sobre redes internacionales) que había sido convocada con motivo de una conferencia de la Universidad de Sussex en Septiembre de 1973. Cerf había sido invitado a presidir el grupo y aprovechó la ocasión para celebrar una reunión de los miembros del INWG, ampliamente representados en esta conferencia de Sussex.
Estas son las directrices básicas que surgieron de la colaboración entre Kahn y Cerf:
- Las comunicaciones entre dos procesos consistirían lógicamente en un larga corriente de bytes; ellos los llamaban "octetos". La posición de un octeto dentro de esta corriente de datos sería usada para identificarlo.
- El control del flujo se realizaría usando ventanas deslizantes y acuse de recibo. El destinatario podría decidir cuando enviar acuse de recibo y cada uno devuelto correspondería a todos los paquetes recibidos hasta el momento.
- Se dejó abierto el modo exacto en que emisor y destinatario acordarían los parámetros sobre los tamaños de las ventanas a usar. Se usaron inicialmente valores por defecto.
- Aunque en aquellos momentos Ethernet estaba en desarrollo en el PARC de Xerox, la proliferación de LANs no había sido prevista entonces y mucho menos la de PCs y estaciones de trabajo. El modelo original fue concebido como un conjunto, que se esperaba reducido, de redes de ámbito nacional tipo ARPANET. De este modo, se usó una dirección IP de 32 bits, de la cual los primeros 8 identificaban la red y los restantes 24 designaban el host dentro de dicha red. La decisión de que 256 redes sería suficiente para el futuro previsible debió empezar a reconsiderarse en cuanto las LANs empezaron a aparecer a finales de los setenta.
 Una de las motivaciones iniciales de ARPANET e Internet fue compartir recursos, por ejemplo, permitiendo que usuarios de redes de paquetes sobre radio pudieran acceder a sistemas de tiempo compartido conectados a ARPANET. Conectar las dos redes era mucho más económico que duplicar estos carísimos ordenadores. Sin embargo, mientras la transferencia de ficheros y el login remoto (Telnet) eran aplicaciones muy importantes, de todas las de esta época probablemente sea el correo electrónico la que haya tenido un impacto más significativo. El correo electrónico dio lugar a un nuevo modelo de comunicación entre las personas y cambió la naturaleza de la colaboración. Su influencia se manifestó en primer lugar en la construcción de la propia Internet (como veremos más adelante), y posteriormente, en buena parte de la sociedad.
Se propusieron otras aplicaciones en los primeros tiempos de Internet, desde la comunicación vocal basada en paquetes (precursora de la telefonía sobre Internet) o varios modelos para compartir ficheros y discos, hasta los primeros "programas-gusano" que mostraban el concepto de agente (y, por supuesto, de virus). Un concepto clave en Internet es que no fue diseñada para una única aplicación sino como una infraestructura general dentro de la que podrían concebirse nuevos servicios, como con posterioridad demostró la aparición de la World Wide Web. Este fue posible solamente debido a la orientación de propósito general que tenía el servicio implementado mediante TCP e IP.
Continuar leyendo
Una de las motivaciones iniciales de ARPANET e Internet fue compartir recursos, por ejemplo, permitiendo que usuarios de redes de paquetes sobre radio pudieran acceder a sistemas de tiempo compartido conectados a ARPANET. Conectar las dos redes era mucho más económico que duplicar estos carísimos ordenadores. Sin embargo, mientras la transferencia de ficheros y el login remoto (Telnet) eran aplicaciones muy importantes, de todas las de esta época probablemente sea el correo electrónico la que haya tenido un impacto más significativo. El correo electrónico dio lugar a un nuevo modelo de comunicación entre las personas y cambió la naturaleza de la colaboración. Su influencia se manifestó en primer lugar en la construcción de la propia Internet (como veremos más adelante), y posteriormente, en buena parte de la sociedad.
Se propusieron otras aplicaciones en los primeros tiempos de Internet, desde la comunicación vocal basada en paquetes (precursora de la telefonía sobre Internet) o varios modelos para compartir ficheros y discos, hasta los primeros "programas-gusano" que mostraban el concepto de agente (y, por supuesto, de virus). Un concepto clave en Internet es que no fue diseñada para una única aplicación sino como una infraestructura general dentro de la que podrían concebirse nuevos servicios, como con posterioridad demostró la aparición de la World Wide Web. Este fue posible solamente debido a la orientación de propósito general que tenía el servicio implementado mediante TCP e IP.
Continuar leyendo
sábado, 22 de marzo de 2008
 La ARPANET original evolucionó hacia Internet. Internet se basó en la idea de que habría múltiples redes independientes, de diseño casi arbitrario, empezando por ARPANET como la red pionera de conmutación de paquetes, pero que pronto incluiría redes de paquetes por satélite, redes de paquetes por radio y otros tipos de red. Internet como ahora la conocemos encierra una idea técnica clave, la de arquitectura abierta de trabajo en red. Bajo este enfoque, la elección de cualquier tecnología de red individual no respondería a una arquitectura específica de red sino que podría ser seleccionada libremente por un proveedor e interactuar con las otras redes a través del metanivel de la arquitectura de Internetworking (trabajo entre redes). Hasta ese momento, había un sólo método para "federar" redes. Era el tradicional método de conmutación de circuitos, por el cual las redes se interconectaban a nivel de circuito pasándose bits individuales síncronamente a lo largo de una porción de circuito que unía un par de sedes finales. Cabe recordar que Kleinrock había mostrado en 1961 que la conmutación de paquetes era el método de conmutación más eficiente. Juntamente con la conmutación de paquetes, las interconexiones de propósito especial entre redes constituían otra posibilidad. Y aunque había otros métodos limitados de interconexión de redes distintas, éstos requerían que una de ellas fuera usada como componente de la otra en lugar de actuar simplemente como un extremo de la comunicación para ofrecer servicio end-to-end (extremo a extremo).
En una red de arquitectura abierta, las redes individuales pueden ser diseñadas y desarrolladas separadamente y cada una puede tener su propia y única interfaz, que puede ofrecer a los usuarios y/u otros proveedores, incluyendo otros proveedores de Internet. Cada red puede ser diseñada de acuerdo con su entorno específico y los requerimientos de los usuarios de aquella red. No existen generalmente restricciones en los tipos de red que pueden ser incorporadas ni tampoco en su ámbito geográfico, aunque ciertas consideraciones pragmáticas determinan qué posibilidades tienen sentido. La idea de arquitectura de red abierta fue introducida primeramente por Kahn un poco antes de su llegada a la DARPA en 1972. Este trabajo fue originalmente parte de su programa de paquetería por radio, pero más tarde se convirtió por derecho propio en un programa separado. Entonces, el programa fue llamado Internetting. La clave para realizar el trabajo del sistema de paquetería por radio fue un protocolo extremo a extremo seguro que pudiera mantener la comunicación efectiva frente a los cortes e interferencias de radio y que pudiera manejar las pérdidas intermitentes como las causadas por el paso a través de un túnel o el bloqueo a nivel local. Kahn pensó primero en desarrollar un protocolo local sólo para la red de paquetería por radio porque ello le hubiera evitado tratar con la multitud de sistemas operativos distintos y continuar usando NCP.
La ARPANET original evolucionó hacia Internet. Internet se basó en la idea de que habría múltiples redes independientes, de diseño casi arbitrario, empezando por ARPANET como la red pionera de conmutación de paquetes, pero que pronto incluiría redes de paquetes por satélite, redes de paquetes por radio y otros tipos de red. Internet como ahora la conocemos encierra una idea técnica clave, la de arquitectura abierta de trabajo en red. Bajo este enfoque, la elección de cualquier tecnología de red individual no respondería a una arquitectura específica de red sino que podría ser seleccionada libremente por un proveedor e interactuar con las otras redes a través del metanivel de la arquitectura de Internetworking (trabajo entre redes). Hasta ese momento, había un sólo método para "federar" redes. Era el tradicional método de conmutación de circuitos, por el cual las redes se interconectaban a nivel de circuito pasándose bits individuales síncronamente a lo largo de una porción de circuito que unía un par de sedes finales. Cabe recordar que Kleinrock había mostrado en 1961 que la conmutación de paquetes era el método de conmutación más eficiente. Juntamente con la conmutación de paquetes, las interconexiones de propósito especial entre redes constituían otra posibilidad. Y aunque había otros métodos limitados de interconexión de redes distintas, éstos requerían que una de ellas fuera usada como componente de la otra en lugar de actuar simplemente como un extremo de la comunicación para ofrecer servicio end-to-end (extremo a extremo).
En una red de arquitectura abierta, las redes individuales pueden ser diseñadas y desarrolladas separadamente y cada una puede tener su propia y única interfaz, que puede ofrecer a los usuarios y/u otros proveedores, incluyendo otros proveedores de Internet. Cada red puede ser diseñada de acuerdo con su entorno específico y los requerimientos de los usuarios de aquella red. No existen generalmente restricciones en los tipos de red que pueden ser incorporadas ni tampoco en su ámbito geográfico, aunque ciertas consideraciones pragmáticas determinan qué posibilidades tienen sentido. La idea de arquitectura de red abierta fue introducida primeramente por Kahn un poco antes de su llegada a la DARPA en 1972. Este trabajo fue originalmente parte de su programa de paquetería por radio, pero más tarde se convirtió por derecho propio en un programa separado. Entonces, el programa fue llamado Internetting. La clave para realizar el trabajo del sistema de paquetería por radio fue un protocolo extremo a extremo seguro que pudiera mantener la comunicación efectiva frente a los cortes e interferencias de radio y que pudiera manejar las pérdidas intermitentes como las causadas por el paso a través de un túnel o el bloqueo a nivel local. Kahn pensó primero en desarrollar un protocolo local sólo para la red de paquetería por radio porque ello le hubiera evitado tratar con la multitud de sistemas operativos distintos y continuar usando NCP.
 Sin embargo, NCP no tenía capacidad para direccionar redes y máquinas más allá de un destino IMP en ARPANET y de esta manera se requerían ciertos cambios en el NCP. La premisa era que ARPANET no podía ser cambiado en este aspecto. El NCP se basaba en ARPANET para proporcionar seguridad extremo a extremo. Si alguno de los paquetes se perdía, el protocolo y presumiblemente cualquier aplicación soportada sufriría una grave interrupción. En este modelo, el NCP no tenía control de errores en el host porque ARPANET había de ser la única red existente y era tan fiable que no requería ningún control de errores en la parte de los hosts.
Así, Kahn decidió desarrollar una nueva versión del protocolo que pudiera satisfacer las necesidades de un entorno de red de arquitectura abierta. El protocolo podría eventualmente ser denominado "Transmisson-Control Protocol/Internet Protocol" (TCP/IP, protocolo de control de transmisión /protocolo de Internet). Así como el NCP tendía a actuar como un driver (manejador) de dispositivo, el nuevo protocolo sería más bien un protocolo de comunicaciones.
Continuar leyendo
Sin embargo, NCP no tenía capacidad para direccionar redes y máquinas más allá de un destino IMP en ARPANET y de esta manera se requerían ciertos cambios en el NCP. La premisa era que ARPANET no podía ser cambiado en este aspecto. El NCP se basaba en ARPANET para proporcionar seguridad extremo a extremo. Si alguno de los paquetes se perdía, el protocolo y presumiblemente cualquier aplicación soportada sufriría una grave interrupción. En este modelo, el NCP no tenía control de errores en el host porque ARPANET había de ser la única red existente y era tan fiable que no requería ningún control de errores en la parte de los hosts.
Así, Kahn decidió desarrollar una nueva versión del protocolo que pudiera satisfacer las necesidades de un entorno de red de arquitectura abierta. El protocolo podría eventualmente ser denominado "Transmisson-Control Protocol/Internet Protocol" (TCP/IP, protocolo de control de transmisión /protocolo de Internet). Así como el NCP tendía a actuar como un driver (manejador) de dispositivo, el nuevo protocolo sería más bien un protocolo de comunicaciones.
Continuar leyendo
viernes, 21 de marzo de 2008
 La primera descripción documentada acerca de las interacciones sociales que podrían ser propiciadas a través del networking (trabajo en red) está contenida en una serie de memorándums escritos por J.C.R. Licklider, del Massachusetts Institute of Technology, en Agosto de 1962, en los cuales Licklider discute sobre su concepto de Galactic Network (Red Galáctica). El concibió una red interconectada globalmente a través de la que cada uno pudiera acceder desde cualquier lugar a datos y programas. En esencia, el concepto era muy parecido a la Internet actual. Licklider fue el principal responsable del programa de investigación en ordenadores de la DARPA (Defense Advanced Research Projects Agency, Agencia de Proyectos de Investigación Avanzada para la Defensa) desde Octubre de 1962. Mientras trabajó en DARPA convenció a sus sucesores Ivan Sutherland, Bob Taylor, y el investigador del MIT Lawrence G. Roberts de la importancia del concepto de trabajo en red.
En Julio de 1961 Leonard Kleinrock publicó desde el MIT el primer documento sobre la teoría de conmutación de paquetes. Kleinrock convenció a Roberts de la factibilidad teórica de las comunicaciones vía paquetes en lugar de circuitos, lo cual resultó ser un gran avance en el camino hacia el trabajo informático en red. El otro paso fundamental fue hacer dialogar a los ordenadores entre sí. Para explorar este terreno, en 1965, Roberts conectó un ordenador TX2 en Massachusetts con un Q-32 en California a través de una línea telefónica conmutada de baja velocidad, creando así la primera (aunque reducida) red de ordenadores de área amplia jamás construida. El resultado del experimento fue la constatación de que los ordenadores de tiempo compartido podían trabajar juntos correctamente, ejecutando programas y recuperando datos a discreción en la máquina remota, pero que el sistema telefónico de conmutación de circuitos era totalmente inadecuado para esta labor. La convicción de Kleinrock acerca de la necesidad de la conmutación de paquetes quedó pues confirmada.
A finales de 1966 Roberts se trasladó a la DARPA a desarrollar el concepto de red de ordenadores y rápidamente confeccionó su plan para ARPANET, publicándolo en 1967. En la conferencia en la que presentó el documento se exponía también un trabajo sobre el concepto de red de paquetes a cargo de Donald Davies y Roger Scantlebury del NPL. Scantlebury le habló a Roberts sobre su trabajo en el NPL así como sobre el de Paul Baran y otros en RAND. El grupo RAND había escrito un documento sobre redes de conmutación de paquetes para comunicación vocal segura en el ámbito militar, en 1964. Ocurrió que los trabajos del MIT (1961-67), RAND (1962-65) y NPL (1964-67) habían discurrido en paralelo sin que los investigadores hubieran conocido el trabajo de los demás. La palabra packet (paquete) fue adoptada a partir del trabajo del NPL y la velocidad de la línea propuesta para ser usada en el diseño de ARPANET fue aumentada desde 2,4 Kbps hasta 50 Kbps.
En Agosto de 1968, después de que Roberts y la comunidad de la DARPA hubieran refinado la estructura global y las especificaciones de ARPANET, DARPA lanzó un RFQ para el desarrollo de uno de sus componentes clave: los conmutadores de paquetes llamados interface message processors (IMPs, procesadores de mensajes de interfaz). El RFQ fue ganado en Diciembre de 1968 por un grupo encabezado por Frank Heart, de Bolt Beranek y Newman (BBN). Así como el equipo de BBN trabajó en IMPs con Bob Kahn tomando un papel principal en el diseño de la arquitectura de la ARPANET global, la topología de red y el aspecto económico fueron diseñados y optimizados por Roberts trabajando con Howard Frank y su equipo en la Network Analysis Corporation, y el sistema de medida de la red fue preparado por el equipo de Kleinrock de la Universidad de California, en Los Angeles.
La primera descripción documentada acerca de las interacciones sociales que podrían ser propiciadas a través del networking (trabajo en red) está contenida en una serie de memorándums escritos por J.C.R. Licklider, del Massachusetts Institute of Technology, en Agosto de 1962, en los cuales Licklider discute sobre su concepto de Galactic Network (Red Galáctica). El concibió una red interconectada globalmente a través de la que cada uno pudiera acceder desde cualquier lugar a datos y programas. En esencia, el concepto era muy parecido a la Internet actual. Licklider fue el principal responsable del programa de investigación en ordenadores de la DARPA (Defense Advanced Research Projects Agency, Agencia de Proyectos de Investigación Avanzada para la Defensa) desde Octubre de 1962. Mientras trabajó en DARPA convenció a sus sucesores Ivan Sutherland, Bob Taylor, y el investigador del MIT Lawrence G. Roberts de la importancia del concepto de trabajo en red.
En Julio de 1961 Leonard Kleinrock publicó desde el MIT el primer documento sobre la teoría de conmutación de paquetes. Kleinrock convenció a Roberts de la factibilidad teórica de las comunicaciones vía paquetes en lugar de circuitos, lo cual resultó ser un gran avance en el camino hacia el trabajo informático en red. El otro paso fundamental fue hacer dialogar a los ordenadores entre sí. Para explorar este terreno, en 1965, Roberts conectó un ordenador TX2 en Massachusetts con un Q-32 en California a través de una línea telefónica conmutada de baja velocidad, creando así la primera (aunque reducida) red de ordenadores de área amplia jamás construida. El resultado del experimento fue la constatación de que los ordenadores de tiempo compartido podían trabajar juntos correctamente, ejecutando programas y recuperando datos a discreción en la máquina remota, pero que el sistema telefónico de conmutación de circuitos era totalmente inadecuado para esta labor. La convicción de Kleinrock acerca de la necesidad de la conmutación de paquetes quedó pues confirmada.
A finales de 1966 Roberts se trasladó a la DARPA a desarrollar el concepto de red de ordenadores y rápidamente confeccionó su plan para ARPANET, publicándolo en 1967. En la conferencia en la que presentó el documento se exponía también un trabajo sobre el concepto de red de paquetes a cargo de Donald Davies y Roger Scantlebury del NPL. Scantlebury le habló a Roberts sobre su trabajo en el NPL así como sobre el de Paul Baran y otros en RAND. El grupo RAND había escrito un documento sobre redes de conmutación de paquetes para comunicación vocal segura en el ámbito militar, en 1964. Ocurrió que los trabajos del MIT (1961-67), RAND (1962-65) y NPL (1964-67) habían discurrido en paralelo sin que los investigadores hubieran conocido el trabajo de los demás. La palabra packet (paquete) fue adoptada a partir del trabajo del NPL y la velocidad de la línea propuesta para ser usada en el diseño de ARPANET fue aumentada desde 2,4 Kbps hasta 50 Kbps.
En Agosto de 1968, después de que Roberts y la comunidad de la DARPA hubieran refinado la estructura global y las especificaciones de ARPANET, DARPA lanzó un RFQ para el desarrollo de uno de sus componentes clave: los conmutadores de paquetes llamados interface message processors (IMPs, procesadores de mensajes de interfaz). El RFQ fue ganado en Diciembre de 1968 por un grupo encabezado por Frank Heart, de Bolt Beranek y Newman (BBN). Así como el equipo de BBN trabajó en IMPs con Bob Kahn tomando un papel principal en el diseño de la arquitectura de la ARPANET global, la topología de red y el aspecto económico fueron diseñados y optimizados por Roberts trabajando con Howard Frank y su equipo en la Network Analysis Corporation, y el sistema de medida de la red fue preparado por el equipo de Kleinrock de la Universidad de California, en Los Angeles.
 A causa del temprano desarrollo de la teoría de conmutación de paquetes de Kleinrock y su énfasis en el análisis, diseño y medición, su Network Measurement Center (Centro de Medidas de Red) en la UCLA fue seleccionado para ser el primer nodo de ARPANET. Todo ello ocurrió en Septiembre de 1969, cuando BBN instaló el primer IMP en la UCLA y quedó conectado el primer ordenador host. El proyecto de Doug Engelbart denominado Augmentation of Human Intelect (Aumento del Intelecto Humano) que incluía NLS, un primitivo sistema hipertexto en el Instituto de Investigación de Standford (SRI) proporcionó un segundo nodo. El SRI patrocinó el Network Information Center, liderado por Elizabeth (Jake) Feinler, que desarrolló funciones tales como mantener tablas de nombres de host para la traducción de direcciones así como un directorio de RFCs (Request For Comments). Un mes más tarde, cuando el SRI fue conectado a ARPANET, el primer mensaje de host a host fue enviado desde el laboratorio de Leinrock al SRI. Se añadieron dos nodos en la Universidad de California, Santa Bárbara, y en la Universidad de Utah. Estos dos últimos nodos incorporaron proyectos de visualización de aplicaciones, con Glen Culler y Burton Fried en la UCSB investigando métodos para mostrar funciones matemáticas mediante el uso de "storage displays" (N. del T.: mecanismos que incorporan buffers de monitorización distribuidos en red para facilitar el refresco de la visualización) para tratar con el problema de refrescar sobre la red, y Robert Taylor y Ivan Sutherland en Utah investigando métodos de representación en 3-D a través de la red. Así, a finales de 1969, cuatro ordenadores host fueron conectados cojuntamente a la ARPANET inicial y se hizo realidad una embrionaria Internet. Incluso en esta primitiva etapa, hay que reseñar que la investigación incorporó tanto el trabajo mediante la red ya existente como la mejora de la utilización de dicha red. Esta tradición continúa hasta el día de hoy.
Se siguieron conectando ordenadores rápidamente a la ARPANET durante los años siguientes y el trabajo continuó para completar un protocolo host a host funcionalmente completo, así como software adicional de red. En Diciembre de 1970, el Network Working Group (NWG) liderado por S.Crocker acabó el protocolo host a host inicial para ARPANET, llamado Network Control Protocol (NCP, protocolo de control de red). Cuando en los nodos de ARPANET se completó la implementación del NCP durante el periodo 1971-72, los usuarios de la red pudieron finalmente comenzar a desarrollar aplicaciones.
A causa del temprano desarrollo de la teoría de conmutación de paquetes de Kleinrock y su énfasis en el análisis, diseño y medición, su Network Measurement Center (Centro de Medidas de Red) en la UCLA fue seleccionado para ser el primer nodo de ARPANET. Todo ello ocurrió en Septiembre de 1969, cuando BBN instaló el primer IMP en la UCLA y quedó conectado el primer ordenador host. El proyecto de Doug Engelbart denominado Augmentation of Human Intelect (Aumento del Intelecto Humano) que incluía NLS, un primitivo sistema hipertexto en el Instituto de Investigación de Standford (SRI) proporcionó un segundo nodo. El SRI patrocinó el Network Information Center, liderado por Elizabeth (Jake) Feinler, que desarrolló funciones tales como mantener tablas de nombres de host para la traducción de direcciones así como un directorio de RFCs (Request For Comments). Un mes más tarde, cuando el SRI fue conectado a ARPANET, el primer mensaje de host a host fue enviado desde el laboratorio de Leinrock al SRI. Se añadieron dos nodos en la Universidad de California, Santa Bárbara, y en la Universidad de Utah. Estos dos últimos nodos incorporaron proyectos de visualización de aplicaciones, con Glen Culler y Burton Fried en la UCSB investigando métodos para mostrar funciones matemáticas mediante el uso de "storage displays" (N. del T.: mecanismos que incorporan buffers de monitorización distribuidos en red para facilitar el refresco de la visualización) para tratar con el problema de refrescar sobre la red, y Robert Taylor y Ivan Sutherland en Utah investigando métodos de representación en 3-D a través de la red. Así, a finales de 1969, cuatro ordenadores host fueron conectados cojuntamente a la ARPANET inicial y se hizo realidad una embrionaria Internet. Incluso en esta primitiva etapa, hay que reseñar que la investigación incorporó tanto el trabajo mediante la red ya existente como la mejora de la utilización de dicha red. Esta tradición continúa hasta el día de hoy.
Se siguieron conectando ordenadores rápidamente a la ARPANET durante los años siguientes y el trabajo continuó para completar un protocolo host a host funcionalmente completo, así como software adicional de red. En Diciembre de 1970, el Network Working Group (NWG) liderado por S.Crocker acabó el protocolo host a host inicial para ARPANET, llamado Network Control Protocol (NCP, protocolo de control de red). Cuando en los nodos de ARPANET se completó la implementación del NCP durante el periodo 1971-72, los usuarios de la red pudieron finalmente comenzar a desarrollar aplicaciones.
 En Octubre de 1972, Kahn organizó una gran y muy exitosa demostración de ARPANET en la International Computer Communication Conference. Esta fue la primera demostración pública de la nueva tecnología de red. Fue también en 1972 cuando se introdujo la primera aplicación "estrella": el correo electrónico.
En Marzo, Ray Tomlinson, de BBN, escribió el software básico de envío-recepción de mensajes de correo electrónico, impulsado por la necesidad que tenían los desarrolladores de ARPANET de un mecanismo sencillo de coordinación. En Julio, Roberts expandió su valor añadido escribiendo el primer programa de utilidad de correo electrónico para relacionar, leer selectivamente, almacenar, reenviar y responder a mensajes. Desde entonces, la aplicación de correo electrónico se convirtió en la mayor de la red durante más de una década. Fue precursora del tipo de actividad que observamos hoy día en la World Wide Web, es decir, del enorme crecimiento de todas las formas de tráfico persona a persona.
Continuar leyendo
En Octubre de 1972, Kahn organizó una gran y muy exitosa demostración de ARPANET en la International Computer Communication Conference. Esta fue la primera demostración pública de la nueva tecnología de red. Fue también en 1972 cuando se introdujo la primera aplicación "estrella": el correo electrónico.
En Marzo, Ray Tomlinson, de BBN, escribió el software básico de envío-recepción de mensajes de correo electrónico, impulsado por la necesidad que tenían los desarrolladores de ARPANET de un mecanismo sencillo de coordinación. En Julio, Roberts expandió su valor añadido escribiendo el primer programa de utilidad de correo electrónico para relacionar, leer selectivamente, almacenar, reenviar y responder a mensajes. Desde entonces, la aplicación de correo electrónico se convirtió en la mayor de la red durante más de una década. Fue precursora del tipo de actividad que observamos hoy día en la World Wide Web, es decir, del enorme crecimiento de todas las formas de tráfico persona a persona.
Continuar leyendo
jueves, 20 de marzo de 2008
 Internet ha supuesto una revolución sin precedentes en el mundo de la informática y de las comunicaciones. Los inventos del telégrafo, teléfono, radio y ordenador sentaron las bases para esta integración de capacidades nunca antes vivida. Internet es a la vez una oportunidad de difusión mundial, un mecanismo de propagación de la información y un medio de colaboración e interacción entre los individuos y sus ordenadores independientemente de su localización geográfica.
Internet representa uno de los ejemplos más exitosos de los beneficios de la inversión sostenida y del compromiso de investigación y desarrollo en infraestructuras informáticas. A raíz de la primitiva investigación en conmutación de paquetes, el gobierno, la industria y el mundo académico han sido copartícipes de la evolución y desarrollo de esta nueva y excitante tecnología. Hoy en día, términos como leiner@mcc.com y http: www.acm.org fluyen fácilmente en el lenguaje común de las personas.
Esta pretende ser una historia breve y, necesariamente, superficial e incompleta, de Internet. Existe actualmente una gran cantidad de material sobre la historia, tecnología y uso de Internet. Una búsqueda en cualquier buscador de Internet nos descubrirá una gran cantidad de sitios con material escrito sobre Internet.
Internet ha supuesto una revolución sin precedentes en el mundo de la informática y de las comunicaciones. Los inventos del telégrafo, teléfono, radio y ordenador sentaron las bases para esta integración de capacidades nunca antes vivida. Internet es a la vez una oportunidad de difusión mundial, un mecanismo de propagación de la información y un medio de colaboración e interacción entre los individuos y sus ordenadores independientemente de su localización geográfica.
Internet representa uno de los ejemplos más exitosos de los beneficios de la inversión sostenida y del compromiso de investigación y desarrollo en infraestructuras informáticas. A raíz de la primitiva investigación en conmutación de paquetes, el gobierno, la industria y el mundo académico han sido copartícipes de la evolución y desarrollo de esta nueva y excitante tecnología. Hoy en día, términos como leiner@mcc.com y http: www.acm.org fluyen fácilmente en el lenguaje común de las personas.
Esta pretende ser una historia breve y, necesariamente, superficial e incompleta, de Internet. Existe actualmente una gran cantidad de material sobre la historia, tecnología y uso de Internet. Una búsqueda en cualquier buscador de Internet nos descubrirá una gran cantidad de sitios con material escrito sobre Internet.
 Esta historia gira en torno a cuatro aspectos distintos. Existe una evolución tecnológica que comienza con la primitiva investigación en conmutación de paquetes, ARPANET y tecnologías relacionadas en virtud de la cual la investigación actual continúa tratando de expandir los horizontes de la infraestructura en dimensiones tales como escala, rendimiento y funcionalidades de alto nivel. Hay aspectos de operación y gestión de una infraestructura operacional global y compleja. Existen aspectos sociales, que tuvieron como consecuencia el nacimiento de una amplia comunidad de internautas trabajando juntos para crear y hacer evolucionar la tecnología. Y finalmente, el aspecto de comercialización que desemboca en una transición enormemente efectiva desde los resultados de la investigación hacia una infraestructura informática ampliamente desarrollada y disponible.
Internet hoy en día es una infraestructura informática ampliamente extendida. Su primer prototipo es a menudo denominado National Global or Galactic Information Infrastructure (Infraestructura de Información Nacional Global o Galáctica). Su historia es compleja y comprende muchos aspectos: tecnológico, organizacional y comunitario. Y su influencia alcanza no solamente al campo técnico de las comunicaciones computacionales sino también a toda la sociedad en la medida en que nos movemos hacia el incremento del uso de las herramientas online para llevar a cabo el comercio electrónico, la adquisición de información y la acción en comunidad.
Continuar leyendo
Esta historia gira en torno a cuatro aspectos distintos. Existe una evolución tecnológica que comienza con la primitiva investigación en conmutación de paquetes, ARPANET y tecnologías relacionadas en virtud de la cual la investigación actual continúa tratando de expandir los horizontes de la infraestructura en dimensiones tales como escala, rendimiento y funcionalidades de alto nivel. Hay aspectos de operación y gestión de una infraestructura operacional global y compleja. Existen aspectos sociales, que tuvieron como consecuencia el nacimiento de una amplia comunidad de internautas trabajando juntos para crear y hacer evolucionar la tecnología. Y finalmente, el aspecto de comercialización que desemboca en una transición enormemente efectiva desde los resultados de la investigación hacia una infraestructura informática ampliamente desarrollada y disponible.
Internet hoy en día es una infraestructura informática ampliamente extendida. Su primer prototipo es a menudo denominado National Global or Galactic Information Infrastructure (Infraestructura de Información Nacional Global o Galáctica). Su historia es compleja y comprende muchos aspectos: tecnológico, organizacional y comunitario. Y su influencia alcanza no solamente al campo técnico de las comunicaciones computacionales sino también a toda la sociedad en la medida en que nos movemos hacia el incremento del uso de las herramientas online para llevar a cabo el comercio electrónico, la adquisición de información y la acción en comunidad.
Continuar leyendo
jueves, 6 de marzo de 2008
Un applet es un componente de una aplicación que se ejecuta en el contexto de otro programa, por ejemplo un navegador web. El applet debe ejecutarse en un contenedor, que lo proporciona un programa anfitrión, mediante un plugin, o en aplicaciones como teléfonos móviles que soportan el modelo de programación por applets. A diferencia de un programa, un applet no puede ejecutarse de manera independiente, ofrece información gráfica y a veces interactúa con el usuario, típicamente carece de sesión y tiene privilegios de seguridad restringidos. Un applet normalmente lleva a cabo una función muy específica que carece de uso independiente. Cuando un Navegador carga una página Web que contiene un Applet, este se descarga en el navegador Web y comienza a ejecutarse esto nos permite crear programas que cualquier usuario puede ejecutar con tan solo cargar la página Web en su navegador. Ejemplos comunes de applets son las Java applets y las animaciones Flash. Otro ejemplo es el Windows Media Player utilizado para desplegar archivos de video incrustados en los navegadores como el Internet Explorer. Otros plugins permiten mostrar modelos 3D que funcionan con un applet. Applet de Java Un Java applet es un código Java que carece de un método main, por eso se utiliza principalmente para el trabajo de páginas web, ya que es un subprograma o pequeño programa que es utilizado en una página HTML y representado por una pequeña pantalla gráfica dentro de ésta. Por otra parte, la diferencia entre una aplicación Java y un applet radica en cómo se ejecutan. Para cargar una aplicación Java se utiliza el intérprete de Java. En cambio, un applet se puede cargar y ejecutar desde cualquier explorador que soporte Java (Nescape, Internet Explorer de Windows, Mozilla Firefox, etc.). Entre sus características podemos mencionar un esquema de seguridad que permite que los applets que se ejecutan en el equipo no tengan acceso a partes sensibles, por ejemplo no pueden escribir archivos, a menos que uno mismo le dé los permisos necesarios en el sistema; la desventaja de este enfoque es que la entrega de permisos es engorrosa para el usuario común, lo cual juega en contra de uno de los objetivos de los Java applets: proporcionar una forma fácil de ejecutar aplicaciones desde el navegador web. Ventajas de los applet de Java • Funcionan en Linux, Windows y Mac OS, son multiplataforma • El mismo applet pueden trabajar en "todas" las versiones de Java, y no sólo la última versión del plug-in. Sin embargo, si un applet requiere una versión posterior de la JRE, el cliente se verá obligado a esperar durante la gran descarga. • Es soportado por la mayoría de los navegadores Web • Puede ser almacenado en la memoria cache de la mayoría de los navegadores Web, de modo que se cargará rápidamente cuando se vuelva a cargar la página Web, aunque puede quedar atascado en la caché, causando problemas cuando se liberan nuevas versiones. • Puede tener acceso completo a la máquina en la que se está ejecutando, si el usuario lo permite • Puede ejecutarse con velocidades comparables (pero en general más lento) a la de otros lenguajes compilados, como C + +, pero muchas veces más rápida que la de JavaScript • Puede trasladar el trabajo del servidor al cliente, haciendo una solución Web más escalable tomando en cuenta el número de usuarios / clientes Desventajas de los applet de Java • Requiere el plug-in de Java, que no está disponible por defecto en todos los navegadores web. • Sun no ha creado una implementación del plug-in para los procesadores de 64 bits • No puede iniciar la ejecución hasta que la Máquina virtual de Java está en funcionamiento, y esto puede tomar tiempo la primera vez que se ejecuta un applet. • Si no esta firmado como confiable, tiene un acceso limitado al sistema del usuario - en particular no tiene acceso directo al disco duro del cliente o al portapapeles. • Algunas organizaciones sólo permiten la instalación de software a los administradores. Como resultado, muchos usuarios (sin privilegios para instalar el plug-in en su navegador) no pueden ver los applets. • Un Applet podría exigir una versión específica del JRE. Cómo crear un applet de java Para crear un applet necesitamos escribir una clase que herede de la clase Applet del paquete java.applet.*;
import java.applet.*; public class MiApplet extends Applet { //Cuerpo del ''applet''. }El código anterior declara una nueva clase MiApplet que hereda todas las capacidades de la clase Applet de Java. El resultado es un fichero MiApplet.java. Una vez creada la clase que compone el applet, escribimos el resto del código y después lo compilamos, obteniendo el fichero MiApplet.class. Para poder crear el applet se necesita compilar el código Java en un intérprete.
import java.applet.*; import java.awt.*; import java.util.*; import java.text.DateFormat; public class MiApplet extends Applet implements Runnable { private Thread hilo = null; private Font fuente; private String horaActual = "00:00:00"; public void init() { fuente = new Font("Verdana", Font.BOLD, 24); } public void start() { if (hilo == null) { hilo = new Thread(this, "Reloj"); hilo.start(); } } public void run() { Thread hiloActual = Thread.currentThread(); while (hilo == hiloActual) { //obtener la hora actual Calendar cal = Calendar.getInstance(); Date hora = cal.getTime(); DateFormat df = DateFormat.getTimeInstance(); horaActual = df.format(hora); repaint(); try { Thread.sleep(1000); } catch (InterruptedException e){} } } public void paint(Graphics g) { //Dibujar un rectangulo alrededor del contenedor g.draw3DRect(1, 1, getSize().width-3, getSize().height-3, false); //Establecer la Fuente g.setFont(fuente); //mostrar la Hora g.drawString(horaActual,14,40); } public void stop() { hilo = null; } }Finalmente, para ejecutar el applet hay que crear una página Web que haga referencia al mismo. La etiqueta HTML que permite hacer eso es <applet>:
<html> <applet code="MiApplet.class" width="370" height="270"> </applet> </html>Los parámetros "MiApplet.class", "370" y "270" correspondientes a la ubicación del archivo que contiene la clase, el ancho y el alto del applet, se pueden modificar. Continuar leyendo
lunes, 3 de marzo de 2008
![]() En un principio esta fue una tecnología más, con la necesidad de instalar un plug-in para poder visualizarse. Cualquier webmaster es reacio a incorporar a una página web contenidos para los que sea necesario utilizar plug-ins, pues es de suponer que no todos los tendrán y que se va a marginar a una serie de usuarios. Con el tiempo, flash se ha convertido en un estandar, viene en la instalación básica de los exploradores, se instala automáticamente si el navegador no lo tiene y muchas páginas lo utilizan. Como resultado tenemos que los webmasters o diseñadores del web lo vienen utilizando para crear todo tipo de efectos, en la página principal del sitio o diseñando todas las páginas con Flash.
La clave de Flash es que es un programa de animación vectorial. Esto significa que se pueden crear animaciones complejas: aumentar y reducir elementos de la animación, mover de posición estos objetos, y otras cosas sin que la animación ocupe mucho espacio en el disco. Los vectores con los que trabaja Flash sólo son, por decirlo de alguna manera, siluetas que casi no ocupan espacio y se pueden modificar fácilmente y sin gasto de memoria en disco.
Desde hace tiempo, proliferan los trabajos hechos en Flash y se pueden ver muchas páginas que incorporan animaciones, sonido y efectos realmente interesantes. Flash es un programa que nos permite aplicar toda nuestra creatividad en la web y fulmina muchos de los límites con los que teníamos que enfrentarnos anteriormente en el diseño de webs.
Flash Player usa un modelo de seguridad sandbox, lo cual significa que las aplicaciones Flash que están reproduciéndose en un navegador disponen de recursos muy estrictos y limitados disponibles para ellos. Las aplicaciones, por ejemplo, no pueden leer archivos del disco duro (excepto los datos como cookies que ellos mismos hayan escrito, denominadas SharedObjects). A partir del lanzamiento de Flash Player 7, sólo pueden comunicarse con el dominio del que ellos se originaron, a menos que sea permitido explícitamente por otro dominio.
ActionScript
Es cierto que la interfaz de programación de Flash está basada en JavaScript, pero con base en este lenguaje, fue creado ActionScript. Puede parecer a simple vista que JavaScript y ActionScript son iguales, pero no lo son. Por una parte, JavaScript es un lenguaje de programación estructurada (también llamada programación modular, debido a la característica de poder armar por partes el script) y además se utiliza principalmente para agregarle interactividad a páginas web. Por otra parte, ActionScript, desde su versión 2.0, pasa de ser de programación estructurada a programación orientada a objetos, que trata de ver el entorno de programación como el mundo real, donde cada objeto tiene propiedades como el color, la forma y su ubicación, y métodos (borrar un texto, parar la línea de tiempo, cargar variables u hojas de estilo), y además nos encontramos con un lenguaje más estricto y más amplio donde usted puede crear sus propias clases.
Ejemplo de Flash
En un principio esta fue una tecnología más, con la necesidad de instalar un plug-in para poder visualizarse. Cualquier webmaster es reacio a incorporar a una página web contenidos para los que sea necesario utilizar plug-ins, pues es de suponer que no todos los tendrán y que se va a marginar a una serie de usuarios. Con el tiempo, flash se ha convertido en un estandar, viene en la instalación básica de los exploradores, se instala automáticamente si el navegador no lo tiene y muchas páginas lo utilizan. Como resultado tenemos que los webmasters o diseñadores del web lo vienen utilizando para crear todo tipo de efectos, en la página principal del sitio o diseñando todas las páginas con Flash.
La clave de Flash es que es un programa de animación vectorial. Esto significa que se pueden crear animaciones complejas: aumentar y reducir elementos de la animación, mover de posición estos objetos, y otras cosas sin que la animación ocupe mucho espacio en el disco. Los vectores con los que trabaja Flash sólo son, por decirlo de alguna manera, siluetas que casi no ocupan espacio y se pueden modificar fácilmente y sin gasto de memoria en disco.
Desde hace tiempo, proliferan los trabajos hechos en Flash y se pueden ver muchas páginas que incorporan animaciones, sonido y efectos realmente interesantes. Flash es un programa que nos permite aplicar toda nuestra creatividad en la web y fulmina muchos de los límites con los que teníamos que enfrentarnos anteriormente en el diseño de webs.
Flash Player usa un modelo de seguridad sandbox, lo cual significa que las aplicaciones Flash que están reproduciéndose en un navegador disponen de recursos muy estrictos y limitados disponibles para ellos. Las aplicaciones, por ejemplo, no pueden leer archivos del disco duro (excepto los datos como cookies que ellos mismos hayan escrito, denominadas SharedObjects). A partir del lanzamiento de Flash Player 7, sólo pueden comunicarse con el dominio del que ellos se originaron, a menos que sea permitido explícitamente por otro dominio.
ActionScript
Es cierto que la interfaz de programación de Flash está basada en JavaScript, pero con base en este lenguaje, fue creado ActionScript. Puede parecer a simple vista que JavaScript y ActionScript son iguales, pero no lo son. Por una parte, JavaScript es un lenguaje de programación estructurada (también llamada programación modular, debido a la característica de poder armar por partes el script) y además se utiliza principalmente para agregarle interactividad a páginas web. Por otra parte, ActionScript, desde su versión 2.0, pasa de ser de programación estructurada a programación orientada a objetos, que trata de ver el entorno de programación como el mundo real, donde cada objeto tiene propiedades como el color, la forma y su ubicación, y métodos (borrar un texto, parar la línea de tiempo, cargar variables u hojas de estilo), y además nos encontramos con un lenguaje más estricto y más amplio donde usted puede crear sus propias clases.
Ejemplo de Flash
 En el ejemplo podemos apreciar el sitio web del canta autor Ricardo Arjona, hecho completamente con Flash. Gracias a las ventajas que nos ofrece esta tecnología se pueden ver fragmentos de sus videos clip directamente en la página, escuchar como fondo musical trozos de su último éxito e interactuar con el contenido del sitio apreciando numerosos efectos visuales.
Continuar leyendo
En el ejemplo podemos apreciar el sitio web del canta autor Ricardo Arjona, hecho completamente con Flash. Gracias a las ventajas que nos ofrece esta tecnología se pueden ver fragmentos de sus videos clip directamente en la página, escuchar como fondo musical trozos de su último éxito e interactuar con el contenido del sitio apreciando numerosos efectos visuales.
Continuar leyendo
Suscribirse a:
Entradas (Atom)